Deep learning will transform Chinese word segmentation in NLP
Lei Feng network press: This article is transferred from ResysChina Gao Xiang, the article mainly introduces 1) the method of distinguishing Chinese word segmentation; 2) using deep learning methods to solve the advantages of Chinese word segmentation and its specific applications.
Existing word segmentation
Natural Language Processing (NLP) is one of the most important technologies in the information age. In simple terms, it is a technology that allows computers to understand human language. Among them, word segmentation technology is a relatively basic module. For languages ​​such as English, such as Latin, because there are spaces between the words as the word marginal expression, the words can be easily and accurately extracted. In Chinese and other languages, in addition to punctuation, words are closely linked and there is no obvious word boundary, so it is difficult to extract words. The meaning of word segmentation is very large. In Chinese, the word as the most basic semantic unit, although it also has its own meaning, but the ideographic ability is poor, the meaning is more dispersed, and the word's ideographic ability is stronger and can describe a thing more accurately. Therefore, in natural language processing, words (including word formation) are usually the most basic processing units. In specific applications, for example, in a commonly used search engine, if term is a word granularity, not only the length of the inverted list of each term can be reduced, system performance is improved, and the result of the recall is highly correlated and accurate. For example, if the search query is "accurate," if it is a single-word segmentation, then it is possible to recall a "doc" that you say is indeed reasonable. The word segmentation method is roughly divided into two types: dictionary-based mechanical segmentation, and sequence label segmentation based on statistical models.
Dictionary-based approach
A dictionary-based method is essentially a string matching method that matches a text fragment in a series of texts with an existing dictionary. If it matches, the text fragment serves as a word segmentation result. But dictionaries-based mechanical segmentation can encounter a variety of problems, the most common being ambiguity segmentation problems and unlisted words.
Ambiguity segmentation
Ambiguity slicing refers to the fact that the result of a lexical match given by a lexicographic match is inconsistent or different from the meaning of the original sentence. It is more common in mechanical slicing, such as the following example: “Married and Unmarried People †By means of mechanical slicing, there will be two sorting results: 1, “married/and/and/not yet/married/people/personsâ€; 2, “married//monk/not/married// people". It can be clearly seen that the second segmentation is ambiguous, and it is difficult to avoid such problems by simple mechanical segmentation.
2. Unregistered word recognition
Unlisted word recognition is also called new word discovery. It means that the word does not appear in the dictionary. For example, some new internet vocabulary, such as "net red" and "go you"; some unregistered names and place names; some foreign language translations Words coming from etc. The dictionary-based approach is more difficult to solve the problem of unregistered words. A simple case can be solved by adding a dictionary. However, as the dictionary increases, a new bad case may be introduced and the system's computational complexity will increase.
3. Dictionary-based mechanical segmentation improvement method
In order to solve the problem of ambiguity segmentation, there are many optimization methods for Chinese word segmentation. Common methods include forward maximum matching, inverse maximum matching, minimum word segmentation results, and full path segmentation.
4. Maximum matching method
The forward maximum matching refers to matching a string from left to right. The longer the matching word, the better. For example, "The Institute of Computing, Chinese Academy of Sciences", the result of segmentation according to the longest matching principle in the dictionary is: " "Chinese Academy of Sciences / Institute of Computing", not "Chinese Academy of Sciences / Computing / Institute". However, there are also some bad cases in the forward match. A common example is: “He goes past my home from the eastâ€. Using the forward maximum match will result in the wrong result: “He/From/East/Over/I/Homeâ€.
The reverse maximum matching order is reversed from right to left. If a longer word can be matched, the first choice is preferred. The above example “he passed the home from the east†reverse maximum matching can get the correct result. He/From/ East / Pass / I / Home." But the reverse maximum match also has a badcase: "They should return in Japan yesterday," and the reverse match will get the wrong result "They / yesterday / Japan / should / come back."
For the problem of forward reverse matching, the results of bi-directional segmentation are compared, and the results with the smallest number of segmented words are selected. However, the minimum segmentation result also has a bad case. For example, "He will be in Shanghai in the future." The correct segmentation result is "He/will/come/Shanghai". There are 4 words and the minimum segmentation result is "He/Future/China". Only 3 words.
5. Full segmentation path selection method
The whole segmentation method is to list all possible segmentation combinations and select the best one segmentation path from among them. There are generally n shortest path methods, word-based n-gram models, and so on.
The basic idea of ​​the shortest path method is to compose all the segmentation results into a directed acyclic graph. The result of each cut word is used as a node. The edge between the words is given a weight, and finally the weight and the smallest path are found as the word segmentation result. .
The word-based n-gram model can be regarded as an optimization of the n shortest path method. The difference is that according to the n-gram model, the context of the word is taken into account when constructing the path. Based on the statistical results of the corpus, the sentences are found out. Maximum model probability. In general, there are many cases where an n-gram model of unigram and bigram is used.
Segmentation Method Based on Sequence Labeling
For the problems faced by the dictionary-based mechanical segmentation, especially the recognition of unregistered words, the use of a segmentation method based on statistical models can achieve better results. The word segmentation method based on the statistical model is simply a sequence labeling problem.
In a text, we can label each word according to their position in the word. Commonly used labels have the following four labels: B, Begin, which means that this word is the first word of a word; M, Middle, which means Is the word in the middle of a word; E, End, which means that this is the end of a word; S, Single, which means that it is a word. The process of word segmentation is to input a character into the model, then obtain the corresponding mark sequence, and then segment the word according to the mark sequence. For example: "Observing the data bit is a big data service provider for companies." After the model has been obtained, the ideal labeling sequence is: "BMMESBEBMEBME", and the final word segmentation result of the restoration is "Achievement data/Yes/Enterprise/big data/service provider" .
In the field of NLP, the common models for solving sequence labeling problems are HMM and CRF.
HMM
The Hidden Markov Model (HMM) is very widely used. The basic idea is to find the true hidden state value sequence based on the observation sequence. In the Chinese word segmentation, each character of a piece of text can be regarded as an observation value, and the word position label (BEMS) of this character can be regarded as a hidden state. Using the segmentation of HMM, the statistics of the segmented corpora can be used to obtain the five major elements of the model: initial probability matrix, transition probability matrix, emission probability matrix, observation value set, and state value set. In the probability matrix, the initial probability matrix represents the probability of the first state value of the sequence. In the Chinese word segmentation, theoretically the probability of M and E is zero. The transition probability represents the probability between states, such as the probability of B->M, and the probability of E->S. The launch probability is a conditional probability, indicating the probability of a certain word appearing in the current state. For example, p (person|B) indicates the probability of a person in the case of state B.
With three matrices and two sets, the HMM problem eventually translates into the problem of solving the maximum of the hidden state sequence. The longest use of this problem is the Viterbi algorithm, which is a dynamic programming algorithm. The specific algorithm can refer to the wiki. Encyclopedia entries do not expand in detail here. (https://en.wikipedia.org/wiki/Viterbi_algorithm)

Figure 1: Schematic diagram of HMM model
CRF
CRF (Conditional Random field) is a probabilistic structural model used to annotate and divide structural data. It is commonly used in pattern recognition and machine learning, and is widely used in the fields of natural language processing and image processing. Similar to the HMM, when the observation sequence X and the output sequence Y are input for a given input, the CRF describes the model by defining the conditional probability P(Y|X) instead of the joint probability distribution P(X,Y). The specific algorithm of the CRF algorithm can refer to Wikipedia entries. (https://en.wikipedia.org/wiki/Conditional_random_field)
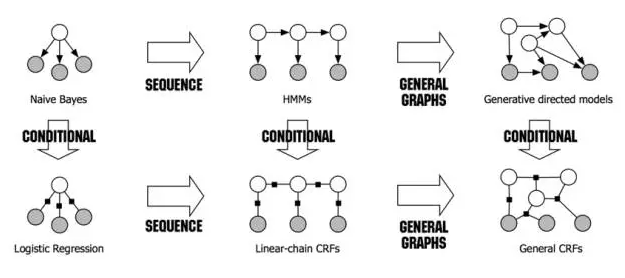
Figure 2: Relationship between different probability models and their evolution
There are many toolkits that can be used in practical applications, such as CRF++, CRFsuite, SGD, Wapiti, etc. The accuracy of CRF++ is higher. When using CRF++ in word segmentation, the main job is the configuration of feature templates. CRF++ supports unigram and bigram features, which begin with U and B respectively. For example, U00:%x[-2,0] represents the first feature, the feature value is the second character in front of the current word, and U01:%x[-1,0] represents the second feature. The value of the word before the current word, U02:%x[0,0] represents the third feature, take the current word, and so on. Feature templates can support a variety of features. CRF++ extracts feature functions based on feature templates for modeling and use. The design of the feature template has a great influence on the word segmentation effect and the training time. It needs analysis to try to find a suitable feature template.
Deep learning introduction
With the great display of AlphaGo, the depth of Deep Learning has further increased. Deep learning comes from the traditional neural network model. The traditional neural network is generally composed of an input layer, a hidden layer, and an output layer. The number of hidden layers is determined as needed. Deep learning can be simply understood as a multilayer neural network, but deep learning is not just a neural network. The depth model takes the output of each layer as the input feature of the next layer and learns by combining the underlying simple features into higher-level, more abstract features. In the training process, greedy algorithms are usually used. Layers of training are used. For example, when the kth layer is trained, the parameters of the pre-k-1 layer of the fixed training are used for training, and after the kth layer is trained, the training is performed one by one. Layer training.
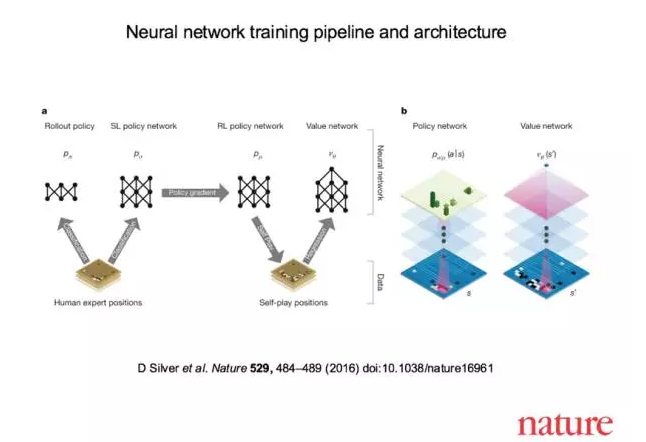
Figure 3: Training Process and Architecture of AlphaGo's Neural Network Model
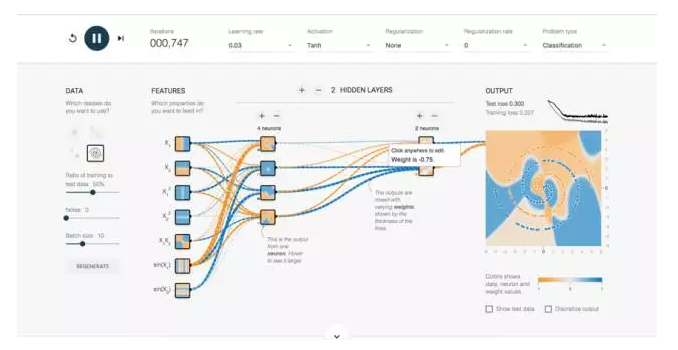
Figure 4: Neural Network Demonstration Diagram of Google Tensorflow Website
Deep learning has been applied in many fields and has achieved great success in the field of image and speech recognition. Since 2012, the Deep Learningd computing framework has been at the forefront of the LLSVC (LargeScale Visual Recognition Challenge) competition. In the 2015 LSRGC (http://LSVRC/2015/results) competition, Microsoft Research Asia (MSRA) won the title in Object Detection and Object Classification + Localization. They use deep neural networks. Up to 152 floors.
Application in NLP
In natural language processing, deep learning has a wide range of applications in machine translation, automatic question and answer, text classification, sentiment analysis, information extraction, sequence annotation, and grammar analysis. The word2vec tool released by Google at the end of 2013 can be seen as an important application of deep learning in the NLP field. Although word2vec has only three neural networks, it has achieved very good results. With word2vec, you can express a word as a word vector, digitize the text, and better understand the computer. To make the word2vec model, we can easily find synonyms or closely related words, or words with opposite meanings.
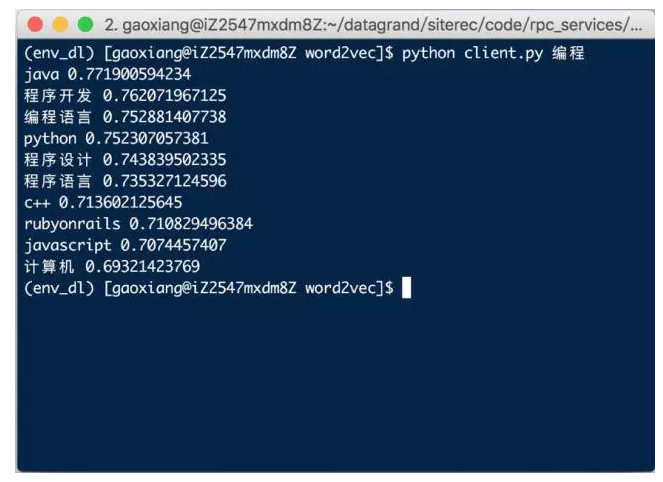
Figure 5: word2vec model test based on WeChat data production: Programming
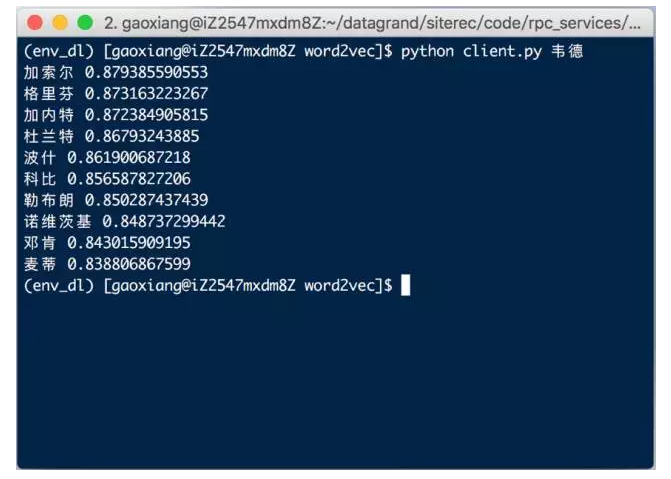
Figure 6: word2vec model test based on WeChat data production: Wade
Word vector introduction
The meaning of a word vector is to represent a word by a vector of numbers. The composition of this vector can have many kinds. The simplest way is the so-called one-hot vector. Assuming that in a corpus, there are a total of n different words, then a vector of length n can be used. For the i-th word (i=0...n-1), the value of the vector index=i is 1. The value of the other positions of the vector is 0, so that a word can be uniquely represented by a vector of the form [0,0,1,...,0,0]. One-hot vector is simple and easy to understand, but there are many problems, such as when adding new words, the length of the entire vector will change, and there is a problem that the dimension is too high to calculate, and the representation of the vector is difficult to reflect two The relationship between words, so the use of less one-hot vectors in general.
If we consider the connection between words and words, we must consider the co-occurrence of words. The simplest is to use a document-based vector representation to give word vectors. The basic idea is also very simple. Suppose there are n documents. If some words often appear in pairs in the same document, we think the two words are very close. For document collections, the document can be numbered (i=0...n-1) and the document can be indexed as a vector index so that there is an n-dimensional vector. When a word appears in a document i, the value at the vector i is 1, so that a word can be represented by a vector of the form [0, 1, 0,..., 1, 0]. Document-based word vectors can well represent the relationship between words, but the length of the vector is related to the size of the corpus, and there will also be dimensionality changes.
Consider a fixed-window-size text fragment to solve the problem of dimensional changes. If two words appear in such a fragment, the two words are considered related. For example, there are three sentences: "I \ like \ you", "I \ love \ sports", "I \ love \ photography", if you consider the size of the window is 1, that is to say that a word and it only Related to the preceding and following words, we can get the following matrix by counting the co-occurrence times:
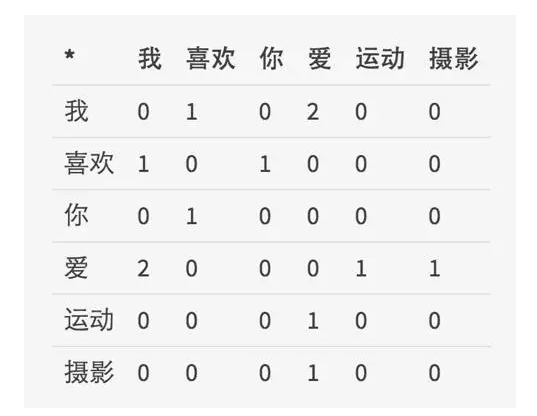
Figure 7: Matrix calculated based on co-occurrence of text windows
It can be seen that this is a symmetrical matrix X of nn. The dimension of this matrix will increase with the number of dictionaries. With SVD (Singular Value Decomposition), we can reduce the dimensions of the matrix but still exist. Some problems: The matrix X dimension often changes, and because most of the words are not sparse due to co-occurrence, the matrix dimension is too high for computational complexity.
Word2vec is a multilayer neural network that can also vectorize words. The two most important models in Word2vec are the CBOW (Continuous Bag-of-Word) model and the Skip-gram (Continuous Skip-gram) model. Both models contain three layers: input layer, projection layer, and output layer. The role of the CBOW model is to know the current context of the word Wt (Wt-2, Wt-1, Wt+1, Wt+2) to predict the current word, and the role of the Skip-gram model is to predict the context based on the current word Wt ( Wt-2, Wt-1, Wt+1, Wt+2). In the model solving, similar to the general machine learning method, it is also to define different loss functions. The gradient descent method is used to find the optimal value. In the Word2vec model solution, Hierarchical Softmax method and NegativeSampling method are used. By using Word2vec, we can easily translate words into vector representations and let the computer understand the performance of digitized words just like every point in the image.
LSTM model introduction
There are many different types of networks for deep learning. In the field of image recognition, the CNN (Convolutional Neural Network) is used more often. In the NLP field, the contextual RNN (Recurrent Neural Networks) is used. Has achieved great success. In the traditional neural network, from the input layer to the hidden layer to the output layer, the layers are fully connected, but the nodes inside each layer are not connected. Because of this reason, traditional neural networks cannot use contextual relationships. In natural language processing, context is very important. Words in a sentence are not independent, and different combinations have different meanings. For example, the word "excellent" If the front is "not", the meaning is completely opposite. RNN takes into account the impact of the output of the network on the current output, and also connects the nodes inside the hidden layer. That is, the input of a node at the current time includes the output of the hidden layer in addition to the output of the previous layer. . RNN theoretically can store transition sequences of any length, but this length may be different in different scenarios. For example, in the word prediction example: "He is a billionaire, he is very?"; 2, "His house costs 40 yuan per square meter, and he has dozens of houses like this. He is very?" . From these two sentences we can already guess that it represents “rich†or other similar words, but it is clear that the first sentence predicts the last word when the upper line sequence is short, while the second line is longer. If predicting a vocabulary requires a long context, RNN will have difficulty learning these long-distance information dependencies as this distance increases, although this is relatively easy for us humans. In practice, the most widely used model has proven to be LSTM (Long Short-Term Memory) to solve this problem.
The LSTM was first proposed by Hochreiter and Schmidhuber in a 1997 paper. First of all, LSTM is also a kind of RNN. The difference is that LSTM can learn long-distance context dependencies and can store the impact of the context from a long distance on the current time node.
All RNNs have a series of duplicate neural network modules. For the standard RNN, this module is relatively simple, such as using a separate tanh layer. The LSTM has a similar structure, but the difference is that each module of the LSTM has a more complex neural network structure: 4 layers of interacting neural networks. In each cell of the LSTM, the LSTM has the ability to increase or decrease information for each cell's transition due to the presence of the gate structure.
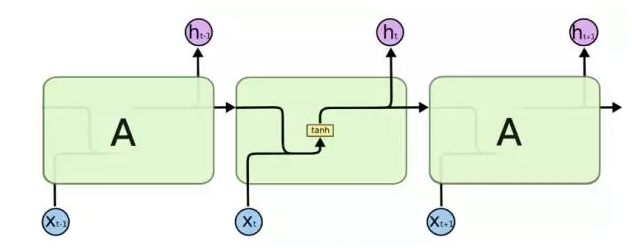
Figure 8: The repeat module in the standard RNN model includes a layer 1 structure
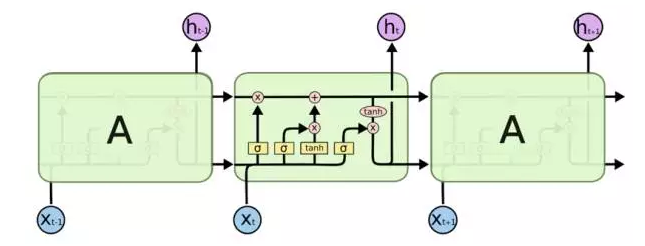
Figure 9: Repeating module in LSTM model includes 4-layer structure
Deep Learning Library Keras Introduction
Keras (http://keras.io) is a very easy-to-use deep learning framework written in Python. It is a highly modular neural network library. The backend supports both Theano and TensorFlow, while Theano and TensorFlow support GPUs. So using keras can use GPU acceleration model training. Keras includes modules used for building models, such as Optimizers optimization method module, Activations activation function module, Initializations initialization module, Layers network layer module, etc. It is very convenient and quick to build a network model, so that developers can quickly get started. And focus on the design of the model rather than the specific implementation. Common neural network models such as CNN, RNN, etc., can be built quickly using keras. Developers only need to throw data into network training in the format required by keras. If there is more demand for the layer that comes with keras, keras can also customize the required layer.
Application of Keras in NLP
The example in the Keras project comes with a number of examples, including the classic mnist handwriting recognition test, among which there are many examples related to NLP, such as sentiment analysis, text classification, and sequence labeling based on imdb data. The lstm_text_generation.py example can be used to refer to the design sequence annotation problem. This example attempts to learn Nietzsche's work through LSTM and train a text generator model through the idea of ​​sequence annotation. The following highlights two key points: model data format and model design.
Training data preparation

This code is data preparation. Nietzsche's full-text data cutting was performed. Each 40-character character was a fragment, and the character immediately following the fragment was used as a predictor for training. The interval of character fragments is 3.
Model design

In the model design, two layers of LSTMs are used. The output dimension of each layer is 512. Dropout layers are added behind each layer of LSTM to prevent over-fitting. The input dimension of the entire model is the number of character categories, the length of the input string is 40, and the output dimension of the model is also the length of the character category. The entire model expresses that for every 40 characters entered, a predicted character is output from the model. Because LSTM's long-term dependence on the memory of term, it can also perform well in the context of long (40 characters).
Segmentation Attempt Based on Deep Learning
Based on the above knowledge, we can consider the use of deep learning methods for Chinese word segmentation. The basic idea of ​​word segmentation is still to use the sequence labeling problem, marking each word in a sentence as BEMS four labels. The entire input to the model is a sequence of characters, and the output is an annotated sequence, so this is a standard sequence to sequence problem. Because the context of each word in a sentence has a great influence on the label type of this word, consider using the RNN model to solve it.
Environment introduction
The test hardware is a Macbook Pro 2014 Mid high version with an NvidiaGT 750M GPU. Although the GPU performance is limited, the test performance is still stronger than the i7 CPU that comes with mac. To use GPU for model calculation, you need to install Nvidia's cuda related programs and cuDNN library, which will have greater performance. Software uses python2.7, installed keras, theano and related libraries. About Keras GPU training environment construction problems, you can refer to this article (Run Keras on Mac OS with GPU, http://blog.wenhaolee.com/run-keras-on-mac-os-with-gpu/)
Model training
The model training uses the classic Microsoft bakeoff 2005 beta segregated corpus, which takes the training part of the training and takes test as the final test.
Training data preparation
First, all the characters appearing in the training sample are mapped into corresponding numbers, and the text is digitized to form a character-to-data mapping. In word segmentation, the label of a word is strongly influenced by the context. Therefore, referring to the lstm_text_generation.py example mentioned earlier, we treat an input text of length n characters into n vectors of length k, where k is an odd number. For example, when k=7, it means that the context of the first 3 words and the last 3 words of a word is taken into consideration. The seven words are taken as one input, and the output is the label type (BEMS) of this word.
Basic model establishment
Refer to the lstm_text_generation.py model building method, we use a layer of LSTM to build the network, the code is as follows,

Among them, the input dimension input_dim is the total number of character classes, hidden_node is the number of nodes in the hidden layer. In the above model, the first layer of the input layer Embedding is to vectorize the input integer. In the current model, the input is a one-dimensional vector where each value is an integer corresponding to the character. The Embedding layer can vectorize these integers. In simple terms, the word vector for each word is generated. Followed by a layer of LSTM, its output dimension is also the number of nodes in the hidden layer. The role of the Dropout layer is to let some neural nodes not work randomly to prevent overfitting. The Dense layer is the final output, where the number of nb_classes is 4, which represents a character's label.
After the model is established, training is started and repeated 20 times. The training results are as follows:

Figure 10: Base model (1 layer LSTM optimizer RMS prop) training 20 times
After training, we use the test data of msr_test to segment words, and use the icwb2's own script to test the final word segmentation results. The results are as follows:
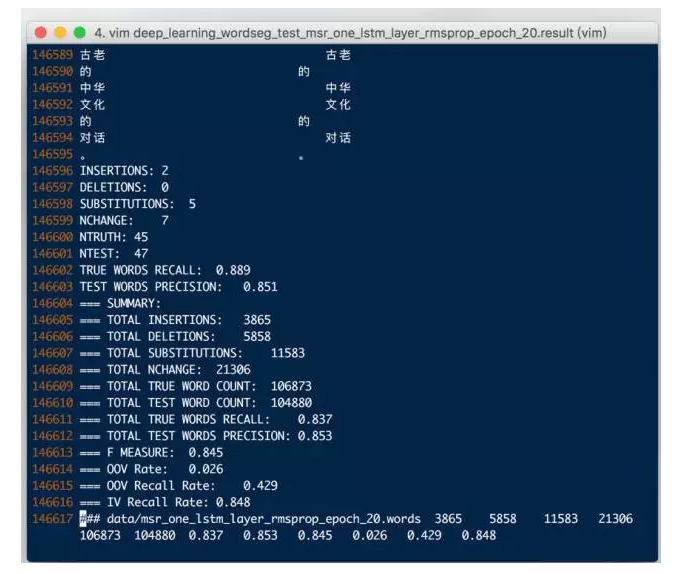
Figure 11: Basic Model F Score: 0.845
It can be seen that the F value of the basic model is generally lower than the traditional CRF, so the optimization model is considered.
Effect improvement
Model parameter adjustment
The first thing that comes to mind is the adjustment of the model parameters. Keras official documents mentioned that RMSprop optimization method is usually a good choice in RNN networks, but after trying other optimizers, such as Adam, it is found that better results can be achieved:
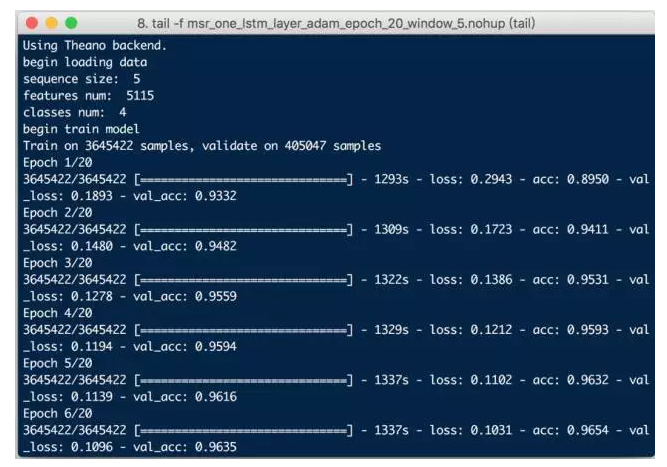
Figure 12: 1 layer LSTM optimizer Adam training 20 times
As you can see, Adam's accuracy during training is already higher than RMSprop, and the test results using icwb2 are:
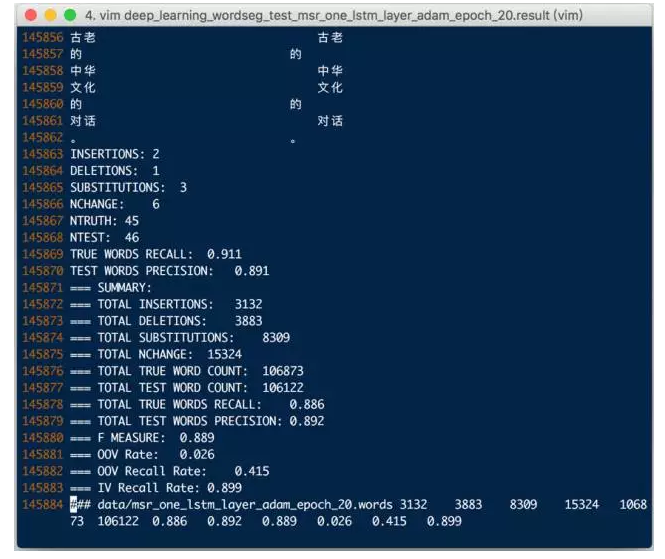
Figure 11: Model after modifying the optimizer Adam F Score: 0.889
Model structure change
Now that the network structure is relatively simple, there is only one layer of LSTM. Refer to the model design in the document example. Consider using two layers of LSTM to test. The modified code is as follows:

Note that the first layer LSTM has a return_sequences = True to export the last result to the output sequence, ensuring that the output tensor is 3D because the LSTM input request is a 3D tensor.
The two-level LSTM model training process is as follows:

Figure 12: Model of the 2-tier LSTM optimizer Adam trained 20 times
It can be seen that the two-layer LSTM makes the model more complex and training often increases. After training the model, the test results using icwb2 are:

Figure 13: Model of two-layer LSTM F Score: 0.889
It can be seen that with the complexity of the model, although there is no improvement in F Score, other indicators have improved. In general, a neural network will have better results with a large amount of training data. Follow-up will continue to try out more complex models with larger datasets.
Summary and outlook
Using deep learning technology, NLP technology has brought new blood to Chinese word segmentation technology, changing the traditional thinking. The advantage of deep neural network is that it can automatically discover features and greatly reduce the workload of feature engineering. With the further development of deep learning technology, it will play a greater role in the field of NLP. Based on the mature NLP algorithms and models, Daguan Data will gradually integrate NLP models based on deep neural networks to further optimize and enhance the functions of text classification, sequence annotation, sentiment analysis, and semantic analysis to better serve customers. service.
Lei Feng Network (Search "Lei Feng Network" public concern) Note: This article is reproduced by ResysChina authorized, please contact the original author if you need to reprint.
N-Type Solar Panel,Mono Solar Pv Panels,Home Made Solar Panel System,Bifacial Solar Panels
JIANGSU BEST ENERGY CO.,LTD , https://www.bestsolar-group.com