ACL2016 Best Paper: Thorough Inspection of CNN/Daily Mail Reading Comprehension Tasks
CNN/ thorough examination of daily mail reading comprehension tasks
Joint compilation: Zhang Min, Chen Chun
Summary
The core goal of the NLP has not yet been resolved is to ensure that the computer understands the document to answer understanding questions. With machine learning systems, a major obstacle to solving this problem is the limited availability of human-annotation data. Hermann et al. sought a solution by generating an instance of more than a million (matching CNN and daily mail messages with their own summarized priorities) and showed that the neural network can be trained to improve performance on this task. In this article, we thoroughly examined this new reading comprehension task. Our main goal is to understand what depth of language understanding is needed in this task. On the one hand, we carefully analyze the small subset of issues manually, and on the other hand, we simply demonstrate that in the two data sets, careful design of the system can yield 72.4% and 75.8% accuracy, which exceeds the current best. The result was 5%, and we achieved the highest performance we believe in this task.
1 Introduction
Reading Comprehension (RC) is also the ability to read articles, process, and understand meanings. How to make computers have this ability is an elusive challenge, and it is also a long-term goal of artificial intelligence (for example, (Norvig, 1978)). True reading comprehension involves interpreting articles and reasoning. Human-reading comprehension is usually tested by asking questions about the understanding of the article, and such an approach is also recommended for testing computers (Burges, 2013).
In recent years, the researchers at DeepMind (Hermann et al., 2015) have been very eye-catching. The original idea to explore this aspect was to try to create for reading comprehension through numerous CNN and Daily Mail news articles with summary points. Large-scale supervision training data for missions. Figure 1 shows an example. The idea is: Summarize one or more aspects of the article. If the computer understands the meaning of the article, it should be able to infer the missing entity in the point.
This is the smartest way to create a supervised data set that is affordable and can be trained on RC models; however, the level of reading required to solve some human tasks is not very clear. In fact, what kind of statistical model has really been learned is the best in this task.
In this article, our goal is to provide an in-depth and rigorous analysis of the article and understand what level of natural language understanding is required before we can do a better job in this task. We have simply proved that careful design system can get the highest precision of 72.4% and 75.8% in CNN and Daily Mail respectively. We did a careful manual analysis of the problem subsets to provide data and the kinds of language understanding needed for success in their difficulties, and we also tried to determine what the system we created learned. We conclude that (i) the data set is simpler than originally thought, (ii) a simple, traditional NLP system that performs better than previous recommendations, and (iii) the distribution of deep learning systems in terms of identifying paraphrases It is very effective, and (iv) partly due to the nature of the problem, the current system has the property of a single sentence relation extraction system compared to the larger discourse contextual text understanding system. (v) The system we propose is close to the highest performance of a single sentence, and the case of a clear set of data. (vi) Properly obtaining the problem The last 20% of the prospects are unsatisfactory because most of them involve preparation questions in the data, which undermines the chance of answering the questions (referring to mistakes or understanding anonymous entities is too difficult). .

Figure 1: Examples of CNN data sets
2. Reading comprehension tasks
The RC data set introduced by Hermann et al. is summarized using the articles and points of CNN and Daily Mail. Figure 1 shows an example: it consists of article p, question q, and answer a. The article is a news site. The problem is that cloze tasks are replaced (the article points are replaced by dashes) and the answer is the essence of the problem. The goal is to infer the missing entity (answer a) from all possible options (given in the article). News articles usually have very few points, and each point emphasizes one aspect of the article.
Articles run through the GoogleNLP channel. It has been carried out, logos, lowercase fonts, recognition of named entities and co-referral resolution. For a unique indicator n, each common-finger chain contains at least one named entity, and all items in the chain are replaced by an @entity n-flag. Hemann et al. (2015) convincingly stated that such a strategy is necessary to ensure that the system accomplishes this task by understanding the articles in front of them, instead of using knowledge of the world without understanding the articles. And language models to answer questions. However, this also gives some tasks that meet the artificial characteristics. On the one hand, the identification of the entity and the instructions that have been executed largely help the system; on the other hand, whether or not the module fails, it will be very difficult (as shown in Figure 1, "properties" should refer to @entity14; In our subsequent data analysis, there are clearer examples of failures. In addition, the use of world knowledge cannot be used, and it also makes it more difficult for humans to perform this task. When an anonymous term is proposed in a way, it is difficult for humans to determine the correct answer.
There are a large number of available news articles on the Internet that make it easy to create data sets, so they provide a large and realistic proving ground for statistical models. Table 1 provides some statistics for two datasets: there are 380k and 879k CNN and Daily Mail training examples. The article has an average of 30 sentences and 800 signs, and each question contains 12-14 signs.
In the following sections, we seek a deeper understanding of the nature of the dataset. We first established some simple systems to better understand the lower boundary performance of current NLP systems. Then, turn to a sample of the data analysis project to check the upper limit of their nature and performance.
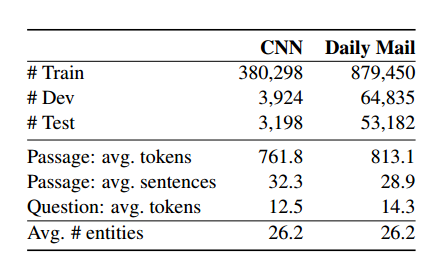
Table 1: Statistics for CNN and Daily Mail datasets. The average mark and sentence of the article, the mark in the query, and the number of entities in the training set that are based on statistics, are very similar in the development and test set.
3. Our system
In this section, we describe two systems implemented—a traditional entity-centric classifier and an end-to-end neural network. Although Hermann et al. provide several baselines for performance in RC tasks, we still doubt that their basics are not strong enough. They tried to use a frame-semantic analyzer. We felt that this small range of parsers undermined the results, and it did not represent a simple NLP system—a standards-based method to state the answers to the questions, and for the past 15 years. The development of the relationship between the extraction (can be achieved). Indeed, their framework-semantic model is clearly inferior to the other baseline they provide, a heuristic word distance model. There are currently only two papers that can be used to demonstrate the results of RC tasks. Both of these papers are based on neural networks: Hermann et al. and Hill et al. While the latter is wrapped in the language of the end-to-end storage network, it actually presents a fairly simple, window-based neural network classifier running on a CNN data set. Its success once again raised the issue of the authenticity and complexity of RC tasks provided by the data set. In this respect, we classified by establishing a simple attention-based neural network classifier.
Given (articles, questions, answers) triples (p, q, a), p={p1, . . ., pm}, q= {q1, . . ., ql} are the result of the article's logo. And the problem statement, using q contains a "@placeholder" flag. The goal is to infer the correct entity a ∈ p ∩ E (corresponding to placeholders), where E is the set of all abstract entity tokens. Note: The correct answer entity must appear in article p.
3.1 Entity-Centric ClassifierWe first establish a traditional feature-based classifier to explore the features that are effective for this task. This is similar to the inspiration of Wang et al. Currently it has extremely competitive performance in the MCTest RC data set (Richardson et al.). The steps of the system are to design a feature vector fpq(e) for each candidate entity e, and to learn a weight vector θ, for example, the correct answer a is higher than all other candidate entities:
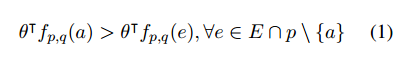
We use the following functional template:
1. Is there entity E in the channel.
2. Is entity E present in the problem?
3. The frequency of entities in the paragraph.
4. The first occurrence of the entity e in the paragraph.
5. n-gram exact match: whether there is an exact match between the text around the placeholder and the entity e around the text. We have the characteristics of all matching combinations, left and/or right one or two words.
6. Word Spacing: We use placeholders for each occurrence of entity e, and compute the average distance of each non-stop question vocabulary to the entities in the paragraph.
7. Sentence symbiosis: In paragraphs of some sentences, entity e occurs with another entity or verb that appears on this question.
8. Dependent analytic matching: We rely on parsing these two questions and all the sentences in the paragraph, and extract the indicator characteristics

3.2 Terminal to Terminal Neural Networks
Our neural network system is based on the AttentiveReader model proposed by Hermann et al. The framework can be described in the next three steps (see Figure 2):
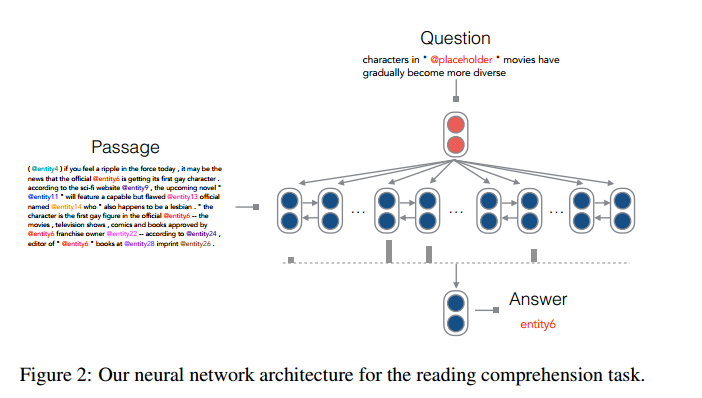
Figure 2: The neural network structure we use for reading comprehension tasks.
Programming:

Attention: In this step, the goal is to compare the embedding of the problem with the embedding of all contexts, and to select the pieces of information that are relevant to the problem. We calculate a probability distribution α that depends on the degree of association between word and word pi (in its context) and problem q, and then produces an output vector O that is a weighted combination of all the context-embedding {pi }:

Prediction: Using the output vector O, the system outputs the most likely answer:
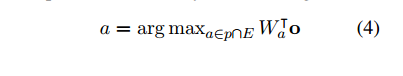
Finally, the system adds a softmax function to Wtap and uses a negative log-likelihood for training.
Unlike Hermann et al., our models basically follow the AttentiveReader. However, to our surprise, our experiments observed that our results improved by nearly 8-10% compared to the original AttentiveReader results on the CNN and Daily Mail datasets (discussed in the fourth section). Specifically, our model has the following differences:
• We use a bilinear term, rather than a hyperbolic tangent layer, for computational problems and context-embedded associations (Note) The effectiveness of simple bilinear attentional functions has been demonstrated in previous neural machine translations ( Luong et al).
· After getting the weighted context embedded in o, we use o for direct prediction. In contrast, before making the final prediction, the original model (Hermann et al.) embeds q through another nonlinear layer combined with o and the problem. We have found that this layer can be removed without compromising performance. And we believe that this is enough to allow model learning to return entities that are given the utmost attention.
The original model considered all the words from the vocabulary V when making predictions. We think this is unnecessary and predict only the entities that appear in the paragraph.
Of these changes, it seems that only the first one is important; the other two are just to keep the model simple. (Min)
Window-based MemN2Ns. Another neural network system approach is based on the memory network structure. We think these two methods are extremely similar in thought. The biggest difference is that the encoding is different: the proof shows that when evaluating a candidate unit, using only 5 words of text is the most effective context-embedding coding: if the window contains 5 words x1,...x5, then Encoded into 5 independent embedded matrices for learning. They can encode placeholders in a similar manner to a 5-word window or any other word that is ignored in question text. In addition, they use only one product point to calculate the "correlation" between problems or textual mosaics. This simple model performs very well because it shows how well the RC task can perform well through local text matching.
4. Test
4.1 Training Details
To train regular classifiers, we applied LambdaMART to RankLib. We use a sorting algorithm because our problem itself is a sorting problem, so it also promotes the recent success of the decision tree system. We do not use all of the features of LambdaMART because only the first recommendation is to sort the 1/0 losses instead of using IR matrix to sort all the results. We use a Stanford neural network-dependent parser to parse text or questions, and other features can be extracted without using additional tools.
In order to train our neural network, we only keep the most commonly used 50k words (including entities and octants), and label all other words. We choose the word's embedded size d=100 and initialize it with a 100-dimensional pre-trained GloVe word. Attention or output is initialized from a uniform allocation (-0.01, 0.01), and LSTM weights are initialized from a Gaussian distribution N (0.01).
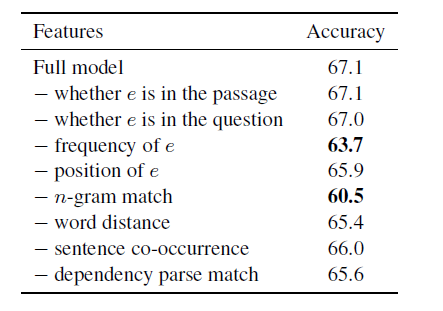
Table 3: Entity-centric classifiers perform feature ablation analysis based on partial development of CNN datasets. The numbers hint at the accuracy of each feature we excluded from all systems, so the smaller numbers suggest an important feature.
The CNN size we use is h=128 and Daily Mail is 256. The optimization is achieved through a stochastic gradient decrement (SGD) with a fixed learning rate of 0.1. We classify based on the text length of all examples, and randomly sample the batch size to 32 for updates. When the scale of the gradient exceeds 10, the drop probability is 0.2 for the embedding layer and gradient clipping.
All of our models are running on a single GPU (GeForce GTX TITAN X) running for 6 hours for each phase of CNN and 15 hours for every phase of DailyMail. We run a model with 30 stages and choose the most accurate model based on the development set.
4.2 Major Achievements
Table 2 shows our major achievements. Feature-based traditional classifiers achieve 67.9% accuracy on the CNN test set. This result not only surpasses other symbolic methods, but also exceeds the results reported by other neural networks in the paper or on a single system. This also shows that this task is not as difficult as it seems, and that a simple feature set can contain many situations. Table 3 shows the feature ablation analysis based on the CNN partial data development entity classifier. This shows that n-gram matching and entity frequency are the two most important categories of feature classification.
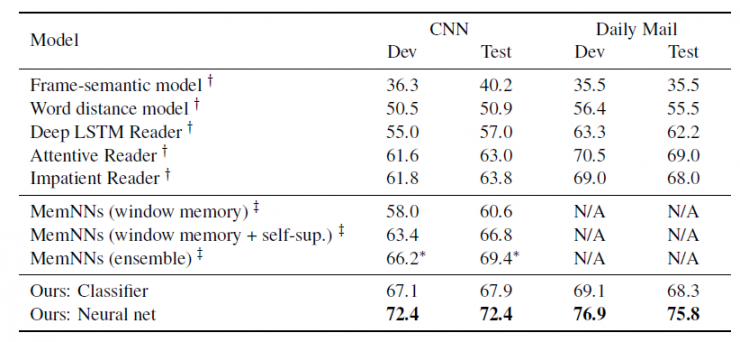
Table 2: Pattern accuracy based on CNN and Daily Mail data sets. Classifiers and neural networks refer to entity center classifiers and neural network systems, respectively. The data that is tagged implies that the result is from integrated mode.
More dramatic, but the results of the pattern neural network significantly exceeded the previous results (more than 5%), and promoted its leading level results to 72.4% or 75.8%. Due to resource constraints, we did not have the opportunity to investigate the integration model, although the integration model can bring better results as described in other papers.
At the same time as our papers, Kadlec et al. and Kabayashi et al. also conducted experiments based on these two data sets, but the results were also excellent. However, our single model not only exceeds them in terms of patterns, but also is simpler in structure. All the recent results have converged into similar data, and we believe that this data is the best result of approaching this task. This conclusion we will explain in the next part.
5. Data Analysis
So far, better results have been obtained through our system. In this section, we are committed to conducting in-depth analysis and answering the following questions: (1) Since the data is created based on automated and heuristics, how many questions are not important? How much is noisy and cannot be answered? (2) What did these models learn? To further improve their prospects? To study this issue, we randomly selected 100 examples for analysis from the development of CNN.
5.1 Example decomposition
After careful analysis of these 100 instances, we have roughly divided them into the following categories (if an example not only satisfies a type, we will classify it in the previous type):
Full match: The word closest to the character also exists in the entity tag; the answer is obvious.
Sentence level definition: The problem text is rewritten in the text with a sentence, so the answer is exactly the same as this sentence.
Local clues: In many cases, although we cannot semantically match the question text with some sentences, the inference can be based on some local clues, such as the matching of some words or concepts.
Multiple sentences: This requires inferring the correct answer by processing multiple sentences.
Referring to errors: It is unavoidable to refer to errors in the data set. This category includes answering entities that appear in the problem or misrepresentation of key entities. In general, we classify this type of problem as "unresponsible."

Table 4: Representative examples of each type.
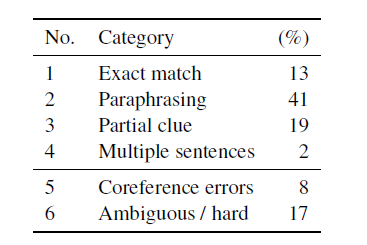
Figure 5: Evaluation of data decomposition based on 100 instances of sampling from CNN datasets.
Obscure or very difficult: The examples contained in this type are questions that we think are difficult for humans to answer.
Table 5 shows the percentage of each type. Table 4 shows each type of representative instance. Surprisingly, based on our manual analysis of “alignment errors†and “fuzziness/difficulty,†which accounted for 25%, this would be an obstacle to increasing accuracy to 75% (of course, models can sometimes guess Accurate.) In addition, only two examples require multiple sentences for reasoning—this is a relatively small probability for Hermann. Therefore, we must assume that in the case of a large logarithm "cannot answer", the goal is to find the relevant (single) sentence and reasoning on the answer based on this single sentence.
5.2 Performance of Each Type
Now, based on the above classification, we further analyze the predictions of these two systems.
As shown in Table 6, our observations are as follows: (1) The situation of complete matching is very simple, and both systems can achieve 100% accuracy. (2) For the obscure/difficult situation or the situation where the entity and the error are connected, as we have predicted, both systems perform poorly. (3) The two systems differ greatly in interpretation and in some cases. This also shows that when it comes to rewriting or when there are differences between the two sentence vocabularies, the neural network system can better match the semantics. (4) We believe that in a single sentence or a clear case, the performance of the nervous system is close to the best performance. Based on this data set, there seems to be no useful headroom for exploring more complex natural language understanding methods.
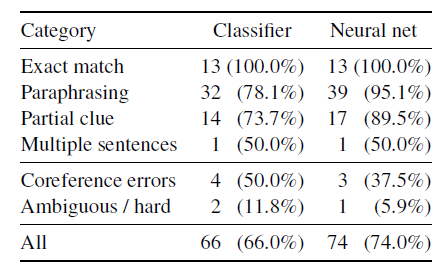
Figure 6: These two modes are represented in each category.
6. Related tasks
We will briefly investigate other tasks related to reading comprehension.
MCTest is an open field issue that is often presented in the form of a short story with multiple choice questions. This is a method created through large-scale exploration. Its goal is to reach a 7-year-old child's level of reading comprehension.
On the one hand, data sets with a variety of reasoning skills are needed: more than 50% of the questions need to be answered by understanding multiple sentences, and the types of questions are also varied (eg, what, why, how, who Which one, etc. On the other hand, the entire dataset contains only a total of 660 paragraphs (each containing 4 questions), which makes training statistical models (especially complex ones) quite difficult.
So far, the best solution is still to rely on manual extraction of semantic or semantic features, as well as additional knowledge (eg, tessellation, semantics, or rewriting data sets).
The Children's Book Test is a task created for a similar purpose based on the CNN/DailyMail data set. Randomly select 20 consecutive sentences from the children's book - the first 20 sentences as a paragraph, the goal is to infer the missing words (questions or answers) in the 21st sentence. These questions can also be classified according to the missing words: physical nouns, ordinary words, prepositions, or verbs. According to the first study of this data set, a language model with local text (n-gram model or recursive neural network) is sufficient to predict verbs or prepositions. However, for predicting physical nouns or common nouns, the results of the prediction can only be improved by browsing the full text.
bAbI is an artificial data set consisting of 20 different inference types. It encourages the development of model chain inference, induction, deduction and other capabilities, so it reads "John in the playground; Bob in the office; John took football; Bob went to the kitchen." Football in the playground" question. Different types of storage networks have shown effectiveness in these tasks. In addition, the spatial vector model based on the analysis of a wide range of problems can exhibit close to perfect accuracy on all types of tasks. Although these results are very good, the data set is limited to a small number of words (100-200 words) and simple language changes, so this is quite different from the data set we need to predict in the real world.
7. Conclusion
In this article, we carefully studied the recent CNN/DailMail reading comprehension task. Our system showed perfect results, but more importantly, we manually conducted careful data analysis.
Overall, we believe that the CNN/Dail Mail dataset is a valuable dataset that provides a good way to train data patterns for reading comprehension tasks. However, we still believe that: (1) The data set is still very noisy because of the data creation method and the reference error; (2) The current recursive neural network has performed optimally on this data set; (3) The reasoning used The data set is still too simple.
In future studies, we will consider how to use these data sets (and models based on these data sets training) to solve more complex problems of reading comprehension (RC) reasoning.
Comments by Associate Professor Li Yanjie of Harbin Institute of Technology: Reading comprehension is the ability to read articles and handle the understanding of the meaning of the articles. How to make computers understand reading comprehension, understand literature, and answer comprehension questions are important and unresolved issues in the field of NLP. A key factor in the learning system's solution to this problem is the limited availability of human annotation data. For this reason, researchers have paired with CNN and daily mailing messages to summarize their own priorities, generating more than one million training data and relying on them. Neural networks better solve the problem of understanding the literature. The paper recommended today conducts a detailed examination of this aspect of the study. Through manual analysis of data sets, and the introduction of entity-centric classifiers and end-to-end neural networks, on the other hand, And solve the above problems and get a higher accuracy.
PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission.