One reads the reliability and durability of data
The more basic and critical concept, the easier it is to misunderstand the sky. The term "reliability", which is constantly mentioned, will be found in carefully distorted misunderstandings and misuses.
One, persistent, usability, silly and indistinct
What we generally call "reliability" is actually a rather ambiguous concept that contains both the meaning of persistence and usability.
Open the AWS S3 introduction page (https://aws.amazon.com/cn/s3/details/) and you will see this sentence:
"Designed to provide 99.999999999% durability and 99.99% availability to the object for the specified year."
This is a very rigorous statement. If you fully understand the meaning of this sentence, you can skip this section and read it.
But if you seem to understand and look at the unpleasant geekiness of the word "persistence", it means that you not only have too many brainteasers, but that the basic knowledge of the database was not learned. The concept of persistence here is a long-lasting concept from the database. The concept of sex draws on.
The meaning of persistence and availability can be understood with the following diagram.
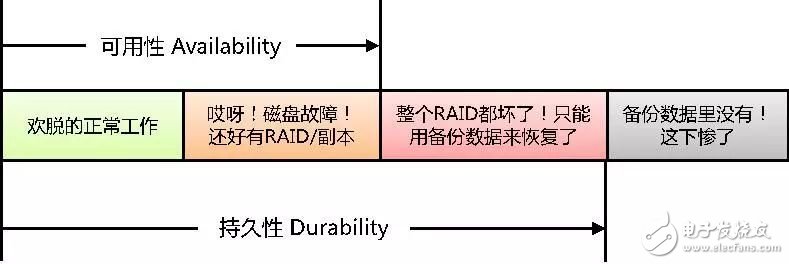
This figure is only a brief description of the meaning, the actual system, there are clusters, disaster recovery and so on all aspects, in order not to spread the focus, the irrelevant nature is omitted.
In simple terms, data access is called available (the translation is very reliable). The data is temporarily inaccessible, but over time it takes some effort to get it back. This state is no longer available, but it is still durable - lasting (this translation is really maddening, but since the early days of the database has been This translation has now become a fixed usage, manual helplessness). Only the data is completely lost, and the state of never finding is beyond the scope of durable.
It can be seen that persistence is more basic than usability, and the former is a necessary and insufficient condition for the latter. From the numerical description, durability ≥ availability.
In addition, boundary conditions need to be defined when discussing persistence and availability. The quantitative index given by the isolated system refers only to the performance of streaking. In actual use, it also depends on what kind of use it is wearing.
For example, the promise given by AWS S3, the meaning of durability 99.999999999%, is that one of the 100000000000 objects may be lost. This is certainly a seemingly reliable system. Suppose you rent 10 billion objects. If you want to see one of them crash, you may have to wait 10 years.
But slowly, there was a naughty questioner on Stack Overflow. He said if there are 10 billion files stored on AWS S3, is it possible to lose files within 10 years?
Given that S3 is mainly used for long-term data archiving and is used at a large scale globally, this question is not a bar. In other words, overbearing as the AWS 11 9 persistence may not be enough to support the vast data of the ocean until the end of time.
Of course, this questioner did not really find any deadlock, and the latter responders quickly told him that as long as the file is saved, adding some verification fault-tolerance mechanisms can keep the S3 object when it collapses. The file is intact.
For those who engage in storage, the reason is too easy to understand, is to do RAID on the S3 object. This mode can be widely used, but if you are not confident about the reliability of a system's streaking, you can think of a way to "RAID" it. Just be careful not to use RAID-0 to increase the probability of failure.
In short, understanding the concepts of persistence and usability, and knowing what is constrained by the equipment and what is at its disposal, and later seeing that product that simply emphasizes a few 9's, will not be easily fooled.
Second, the time boundary and fault law
Generally speaking about persistence and availability, all need to be implicit or explicit and precede the percentage with an “year†limitation. For example, 99% availability means that the annual downtime does not exceed 3.65 days, or 87.6 hours. The availability of 99.9% means that the annual downtime does not exceed 8.76 hours. People often mention five 9 high availability, that is, 99.999% availability, which translates into only 5.256 minutes of downtime each year.
So what is the usability of a domineering side-by-side 5 9-a-year high-availability system in 100 years? In theory, it seems that the 99.9% availability of the prestige is still sufficient (the precise calculation result should be slightly less than 99.90005% and then lost), but this is obviously unreasonable. The strong silicon-based species, which has been weight-bearing for 100 years in the engine room, must have been completely abandoned.
So another implicit limitation of durability and usability - within normal life span. Unfortunately, the definition of the normal life span of silicon-based species is also a mixture of true and false information.
Take the most frequently failed disk devices as an example. Each disk model has an MTBF Mean Time Between Failure (TIMF) to declare its reliability. Specific definitions and explanations can be found everywhere. I will not talk nonsense.
Regarding MTBF, I only have one suggestion:
Do not believe! Do not believe! Never believe it! Three important things to say.
As the main specification indicator of quality, the MTBF of the disk has completely degenerated purely by means of bragging. The value has been counted from tens of thousands of hours at the beginning, and it has gone all the way to the extremely exaggerated millions of hours.
1 million hours = 114 years!
If you really believe that there are disks that can be used for so long, there is no need to look at the rest of this article.
Fortunately, as early as in 2007, several of Google’s big cattle couldn’t live up to such irresponsible nonsense. They slammed hard disk vendors with an essay titled “Failure Trends in a Large Disk Drive PopulaTIonâ€. The paper collected statistics on the operation and maintenance data of tens of thousands of disks and found that the failure probability of enterprise-level disks and desktop-level disks in the actual environment is very close, with almost no difference. However, manufacturers have markedly different MTBF labels for the two disks, and they are even several times different. Regardless of the type of disk, the actual statistical AFR (annual failure rate) is much higher than the estimated value of the MTBF by several orders of magnitude.
By the way, the paper also pointed out that the actual disk AFR will be as high as 3 to 8%, which is much higher than the disk vendor's statistics of 0.4 to 1.2% per year. Where is the difference in this part? It is difficult for people to split.
The statistics object of Google's thesis is to use disks within 5 years. The original factory warranty for disks is also generally 5 years. This lifespan selection comes from the U-shaped distribution law of the disk failure rate.
General disk failure occurred within 3 months of the new on-line or near the end of the warranty period, and the middle stage was relatively eliminated.

The failure of new disks is mainly caused by omissions or errors in the manufacturing process. For example, if the plate body is not tightly sealed, it will soon fail after going online. This is due to the birth of an individual's inborn defects in silicon-based species. Such problems will be fully exposed soon after being loaded for a period of time.
Next, a healthy group of young and old disks remains in the system and the failure rate will naturally drop significantly. However, this kind of disk, which rotates thousands of times per minute, rotates for several tens of thousands of hours after the joyful spin, and it still grinds into embroidery needles and finally usher in the aging period. Then the failure rate began to rise again.
It should be noted that the speed of disk wear is closely related to the working environment and the load. In a relaxed and comfortable environment, you can successfully support a five-year disk, and change to an environment that is heavily loaded and cruel.
From Google's paper, it can be seen that Google's data center must be a sweatshop of a cruel squeeze disk, because the disk inside it has already begun to age significantly in about 2 years. Attach a picture in the paper and let everyone feel it.
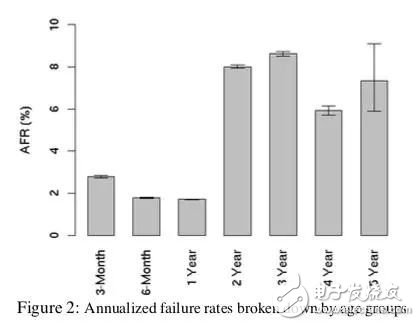
Having said so much, it is concluded that silicon-based species, like our carbon-based species, have a whole life-long process of death. Discussing the reliability of silicon-based species is just like discussing the health of our carbon-based species, not only between individuals, but also because individual conditions change with time and the environment.
Third, the quantitative calculation of reliability
Quantitative calculation of reliability is definitely a hard-hit area where various errors occur frequently. If you search for this kind of calculation method on the Internet, including various calculation formulas and calculation logic from product manufacturers, university research institutions, and community forum freelancers, more than 80% of them have errors and loopholes.
With the actual operation and maintenance experience of the back room of the engine room, after seeing this type of formula that seems to be plausible, the calculation results are very puzzling, and they will be unaware of the reliability of the system and then abandon the scientific and technological beliefs of many years. Resolutely embark on the path of superstition.

In order to save the lost operation and maintenance engineers and rejuvenate the prestige of mathematics and physics and chemistry, we still take a serious look at how reliability is calculated.
For simple systems, I believe that students who graduated from science and engineering are not yet confused.
For example, in a serial system (RAID-0 is typical), the system is healthy when all units are healthy. Therefore, the system health probability calculation method is the multiplication of the health probability of each unit. Similarly, in parallel systems (such as multiple copies), the system fails when all units fail, so the system failure probability is the product of the failure probability of all cells, and the health probability is 1 minus the failure probability.
Brains are warmed up and we now consider a slightly more complicated system.
Assume an n-node distributed storage system with m disks in each node. The system uses k-copy data protection. The replicas are stored across nodes. The health probability of each disk is p, then the overall health probability of the system is What?
Well, I admit, the difficulty jumps a lot, and jumping from the basic concept of warm-up to this is a little less of a fortune. Then we at least consider whether these conditions are sufficient to calculate the reliability of the system and whether there are any additional restrictions.
Hit the blackboard! The point is coming!
Most online error calculation logic actually ignores the same factor—time.
As I mentioned in the previous section, if a unit or system has a reliability of 99% in 1 year, then its reliability in 1 day should be 99.997%, and the reliability in 10 years will become 90.4%. Before the time span is unified, it cannot be quantified. Just like various wealth management products, some earn 2% in 3 months, and some make 20% in 5 years. To compare which of the high returns, you must first convert the income to annualized rate of return. The same is true for reliability. In the calculation process, it is necessary to pay attention to the “annualization†process at all times.
Let's look at the conditions of n, m, k, and p in the new topic. Except that p needs to consider annualization, it seems that the other conditions are not directly related to time. We should be able to start to calculate.
Do not worry first, we also need to consider another issue - what is the state of failure?
Someone will surely blurt out his thoughts, and many discs fail at the same time, and many copies of k will all be broken, that is, fault conditions. However, where is there a strict "simultaneous"? Did all disks fail in the same month or the same year, is it considered "simultaneous"?
I believe that when most people understand what they say, they actually think that the timing of multiple disk failures is too dense, so that before the k copy of all the bad light, it is too late to repair a good data. This is the real meaning of what we often refer to as "multiple simultaneous failures."
Based on this understanding, we know that in determining whether the system is faulty, it actually implies a time factor - the time window required for data repair, also known as the Downgrade window.
This time window is calculated from the first disk failure in a healthy state until it is restored to a healthy state. Which generally includes spare part replacement time t and data reconstruction time Ï„, the total downgrade window is t + Ï„.
Nowadays many distributed storages can shorten this downgrade window and can rebuild bad disks directly in the existing free space. t=0 in this case. Data repair reconstruction requires time overhead anyway, so Ï„ will not always be zero.
We now know that just in that system, we must add t and Ï„ two factors in order to carry out reliability calculations.
At this point, the formula is played. The annual health probability H of the system is calculated as follows:
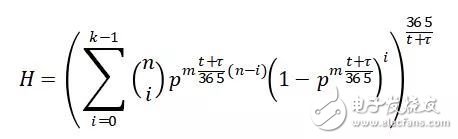
The units of t and Ï„ in the formula are days.
I have to admit that the U-shaped distribution of failures was not considered in the process of deriving this formula, but simply replaced by the average distribution. As for the reasons, of course, I will not admit that I am lazy, I will not sell Meng said waiting for everyone to improve. I just think that the future of mass systems will no longer be planned and constructed in batches like this, but rolling construction will continue. In that case, different batches of equipment in the system are mixed together, and all age groups have, and this U-shaped distribution problem will naturally be ironed out.
Fortunately, for students who don't know how to read the (dong) formula, don't worry about it. I've listed this formula mainly to prove that the science and engineering belief still insists that we shouldn't give up on the fact that there are loopholes in the logic of mistakes. Faith. As long as the factors considered are comprehensive, even in complex systems, the health probability can be quantified.
Interested students can use this formula to draw H(n), H(m), H(t+Ï„) curves to see how each variable affects the change in the system's health probability H. I believe you will have a lot of experience that is in line with actual experience and it is quite a surprise.
I have also done some extended variable plots, which I won't post here. If so, wait until April 14 at the Shenzhen GOPS conference to share with you.
At this GOPS conference, I would also like to introduce a new technology that completely overturns the reliability building logic: disk failure prediction. No place to advertise, you can only use your own article advertising.
Passive Stylus Pen,Custom Stylus Pen,Stylus Pen For Surface,Smart Stylus Pen
Shenzhen Ruidian Technology CO., Ltd , https://www.wisonens.com