MobileNetV2 has been released, it will provide support for the next generation of mobile vision applications
Last year, we introduced MobileNetV1, a general-purpose computer vision neural network series designed for mobile devices, which supports classification and detection functions. Running a deep network on personal mobile devices can improve user experience, allow access anytime and anywhere, and also have advantages in terms of security, privacy, and energy consumption. With the emergence of new applications that allow users to interact with the real world in real time, the demand for more efficient neural networks has gradually increased.
Today, we are happy to announce that MobileNetV2 has been released, which will provide support for the next generation of mobile vision applications.
MobileNetV2 has made significant improvements on the basis of MobileNetV1 and promoted the development of mobile visual recognition technology, including classification, object detection and semantic segmentation. MobileNetV2 is released as part of the TensorFlow-Slim image classification library. You can also browse MobileNetV2 in Colaboratory. Or, you can download the notebook and use Jupyter locally. MobileNetV2 will also be used as a module in TF-Hub, and the pre-training checkpoint is located in github.
MobileNetV2 is based on the concept of MobileNetV1 [1] and uses deep separable convolution as an efficient building block. In addition, V2 introduces two new features in the architecture: 1) linear bottlenecks between layers, and 2) quick connections between bottlenecks. The basic structure is shown below.
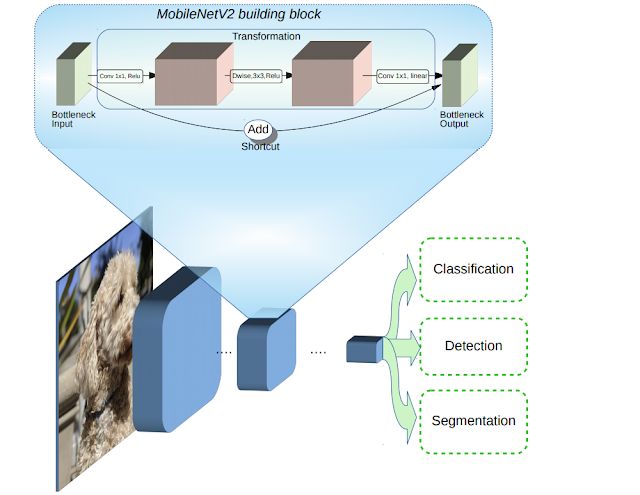
MobileNetV2 architecture overview
The blue block represents the composite convolution building block shown above
We can intuitively understand that the bottleneck layer encodes the intermediate input and output of the model, while the inner layer encapsulates the function that allows the model to convert low-level concepts (such as pixels) into high-level descriptors (such as image categories). Finally, like traditional residual connections, shortcut connections can also improve training speed and accuracy. For detailed technical details, please refer to the paper "MobileNet V2: Inverted Residuals and Linear Bottlenecks".
How is MobileNetV2 different from the first generation MobileNet?
In general, the MobileNetV2 model can achieve the same accuracy faster within the overall delay time range. Especially on the Google Pixel phone, compared with the MobileNetV1 model, the number of operations of the new model is reduced by 2 times, the parameters are reduced by 30%, the speed is increased by 30-40%, and the accuracy is also improved.
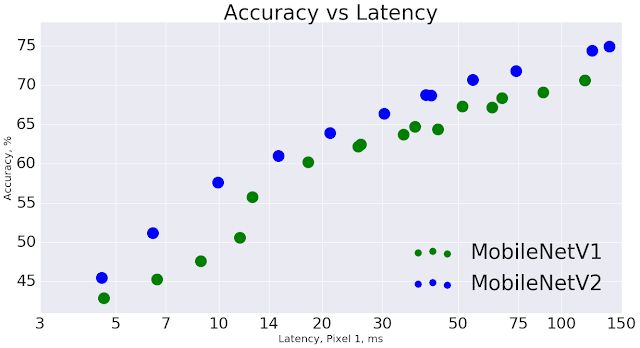
MobileNetV2 improves the speed (reduced latency) and improves the accuracy of ImageNet Top 1
For object detection and segmentation, MobileNetV2 is a very effective feature extractor. For example, in terms of detection, when used with the newly introduced SSDLite [2], the speed of the new model is about 35% faster than MobileNetV1 while achieving the same accuracy. We have open sourced the model under Tensorflow Object Detection API [4].

In order to achieve semantic segmentation on devices, we adopted MobileNetV2 as a feature extractor in the simplified version of DeepLabv3 [3] recently announced. Under the condition of using the semantic segmentation benchmark PASCAL VOC 2012, the performance of the new model is similar to that of using MobileNetV1 as a feature extractor, but the number of parameters of the former is reduced by 5.3 times, and the number of multiplication and addition operations is reduced by 5.2 times.

In summary, MobileNetV2 provides a very efficient model for mobile devices that can be used as the basis for many visual recognition tasks. We are now sharing this model with the broad academic and open source communities, hoping to further promote research and application development.
19V Power Adapter,Desktop Ac/Dc Power Adapter 19V,Ac Dc Adapter 19V,19V 6.3A Power Adapter
ShenZhen Yinghuiyuan Electronics Co.,Ltd , https://www.yhypoweradapter.com