Reinforcement learning environment research, why the agent is good at playing games
Reinforcement learning, as a commonly used method of training agents, can complete many complex tasks. In reinforcement learning, the agent's strategy is trained by maximizing the reward function. The reward is outside the agent, and the reward in each environment is different. The success of deep learning is mostly due to dense and effective reward functions, such as increasing "scores" in video games. However, designing a good reward function requires a lot of effort. Another method is to generate internal rewards, that is, the rewards generated by the agent itself. Internal rewards include "curiosity" (taking prediction errors as reward signals) and "number of visits" (agents are not encouraged to visit the same state). These internal rewards are designed to fill the gap between the sparse external rewards.
But what if there is no external reward for a certain scene? This is not surprising. Developmental psychology believes that internal rewards (such as curiosity) are an important driving force in the early stages of development: babies do not have too many purposes when they explore the world. Indeed, there is evidence that pre-training agents with only internal rewards in a certain environment can allow them to adjust faster in new environments and new tasks. But so far, there is no systematic research on completely internal reward learning.
In this paper, we conducted a large-scale empirical study on the internal rewards of agents in various simulated environments. In particular, we chose the internal reward in the dynamic curiosity model proposed by Pathak et al., because it is scalable and can be calculated in parallel, which can be said to be an ideal tool for large-scale experiments. The core of the research is the current state of a given agent, observing what errors the internal reward will make when predicting the next action. In the study, we investigated a total of 54 environments: including video games, physics engine simulation and virtual 3D navigation tasks. Figure 1:

figure 1
To better understand curiosity-driven learning, we then looked at the key factors that determine its performance. Predicting the future state in the high-dimensional original observation space (such as images) is a very challenging task, and recent studies have shown that dynamic learning in the auxiliary feature space can help improve the results. However, how to choose such an embedding space is very important, and there is no definite conclusion yet. After systematic research, we have checked the effects of different coding methods observed by the agent. In order to ensure the stability of training, we need to choose a good feature space. A good feature space can make prediction easier and filter out factors that have nothing to do with the observation environment. But for curiosity-driven feature spaces, what features are required?
Compact: After filtering out the parts that are not relevant to the observation space in lower dimensions, the features will be easier to model.
Efficient: Features should contain all important information. Otherwise, the agent will not be rewarded after discovering relevant information.
Stability: Non-static rewards make it difficult for the reinforcement agent to learn. In a dynamic curiosity-driven environment, there are two sources of non-static: the pre-dynamic model develops over time, because its characteristics are also changing during training. The former is internal, while the latter should be minimized.
We have found that in many popular reinforcement learning, using random networks to encode observations is a very simple and efficient technique. Interestingly, we found that although random features can perform well in training, the learned features seem to be better than it.
In addition, we found that the important point is that the game will "done" as a signal to end. Without this end signal, many Atari games become easy. For example, if the agent is alive, the reward for each step is +1, and if it is dead, it is 0. For example, in a "brick-breaking" game, the agent should "live" as long as possible and maintain a high score. If a negative reward is received, the agent will end the game as quickly as possible.
Knowing this, we should not be biased against agents when researching. In a limited setting, avoiding death is just another way for the agent to cope, it is just to be less boring. So we deleted "done" and separated the agent's score from the death signal. In fact, we did find that the agent avoids death in the game because there are always many repetitive scenes from the beginning of the game. They can already predict the next action well, so the agent will try to keep "survival" as much as possible. This finding was ignored before.
experiment
The main purpose of analyzing 48 Atari environments is threefold:
In a game with no external rewards, what happens when running an agent driven entirely by curiosity?
What behaviors can you make the agent do?
In these behaviors, what are the effects of different characteristic learning variables?
To answer these questions, we start with a series of Atari games. One way to test how well an agent that uses curiosity is performing is to see how many external rewards it can get. We finally got the average external reward scores of 8 games (excluding Mario on the far right):
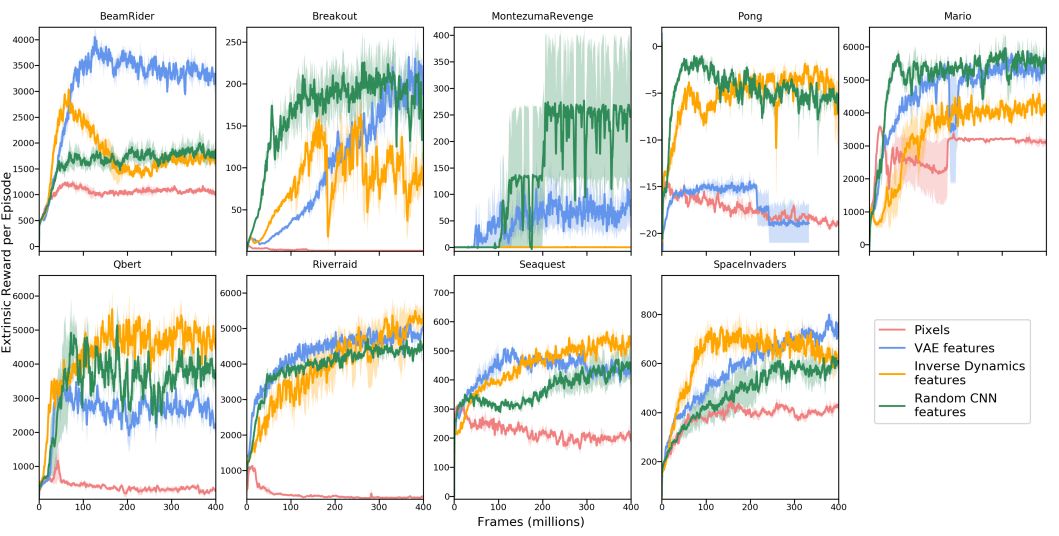
It can be seen that most of the curves show an upward trend, which shows that an agent driven entirely by curiosity can obtain external rewards through learning, even if external rewards are not used during training.
In addition, we also compared the different feature learning performance of Mario Brothers in the above figure. For more experimental results, please see the appendix of the original paper.
discuss
In this research, we have done a lot of research on curiosity-driven reinforcement learning environments, including Atari games, Super Mario Bros, virtual 3D, multiplayer table tennis, etc. Among them, a variety of different feature spaces were investigated, including random features, pixels, inverse dynamics, and autoencoders, and their generalization ability to unfamiliar environments was evaluated.
We prove that trained agents can learn useful behaviors with curiosity rewards. They can play Atari games without rewards; Mario can pass 11 levels without rewards; they can generate walking and acrobatic actions. ; In a two-player ping-pong game, a sparring mode can be generated. But this is not always true. In some Atari games, their exploration does not match the external rewards.
In addition, this result also proves that in an environment designed by humans, the purpose of external rewards may be to allow the target object to innovate. The environment created by game designers is to guide users.
However, there is a serious potential limitation here is dealing with random dynamics. If the transition of the environment is random, then even with a perfect dynamic model, the reward will become the transition entropy, and the agent will look for a transition with a higher entropy. Conversion. Even if the environment is not completely random, the unpredictability caused by the learning algorithm, bad model categories or partial observations can cause the same problem.
In the future, we will prove that we can use a label-free environment to improve task performance.
ZGAR TWISTER Disposable
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

Disposable E-cigarette, ODM disposable electronic cigarette, vape pen atomizer , Device E-cig, OEM disposable electronic cigarette
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.zgarecigarette.com