The basic principle of key point detection technology, the basic method of key point detection
On the afternoon of June 30th, Wu Zizhang conducted a practical sharing on the topic of "Application of Key Point Detection Technology in Visual Perception of Autonomous Driving" in the 29th issue of Qiniu Architect Practice Day. This article is a compilation of the content of the speech.
ZongMu Technology's automatic driving perception algorithm manager, mainly researches target detection, segmentation and tracking in road scenes, and promotes related algorithm performance optimization and embedded transplantation.
In autonomous driving, environmental perception is a very important link. It can not only help unmanned vehicles to locate, but also inform information such as obstacles to help the decision-making module to adjust driving behavior. In visual perception tasks, there are actually many subdivided task types, such as target detection, target tracking, semantic segmentation, instance segmentation, key point detection, etc., and these subdivision tasks are very important in our environmental perception application.
This sharing mainly starts from the following content:
Introduce the basic principles of key point detection technology, the basic method of key point detection, the application of this technology in automatic driving, and the existing problems of key point detection technology, the future development direction and the development potential in automatic driving.
01
Introduction to key point detection technology
In image processing, key points are essentially a feature. It is an abstract description of a fixed area or physical relationship in space, describing a combination or context relationship within a certain neighborhood. It is not only a point of information, or a location, but also a combination of context and surrounding neighborhoods.

For example, in the face key point detection task, there are 28 key points, or 64 or 128 key points that are more popular now, each of which represents a type of feature in a different face, and Has a certain versatility. This type of feature not only includes some characteristics of pixels, such as the feature points of lips, but also the positional relationship between lips and face.
The picture on the right is the clothing key points competition launched by Ali, which was relatively popular some time ago. For example, 13 types of key points are provided in this clothing. The reason why each key point is positioned as a type of key point is because it represents the clothing. A certain location, or the surrounding relationship represented by a certain location. In human body posture detection, this key point not only represents a joint, but also represents the relationship between this joint and other joints, such as which joints can be closely connected with.
02
Two types and methods of key point detection
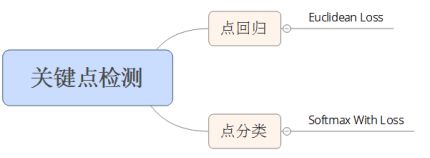
One aspect is to use point regression to solve, the other is to use point classification method. But these two methods are both a means or a way. The problem to be solved is to help us find out the position and relationship of this point in the image.
Principles of key point detection technology
Take the human body key points of openpose as an example. This is a network that everyone is familiar with.
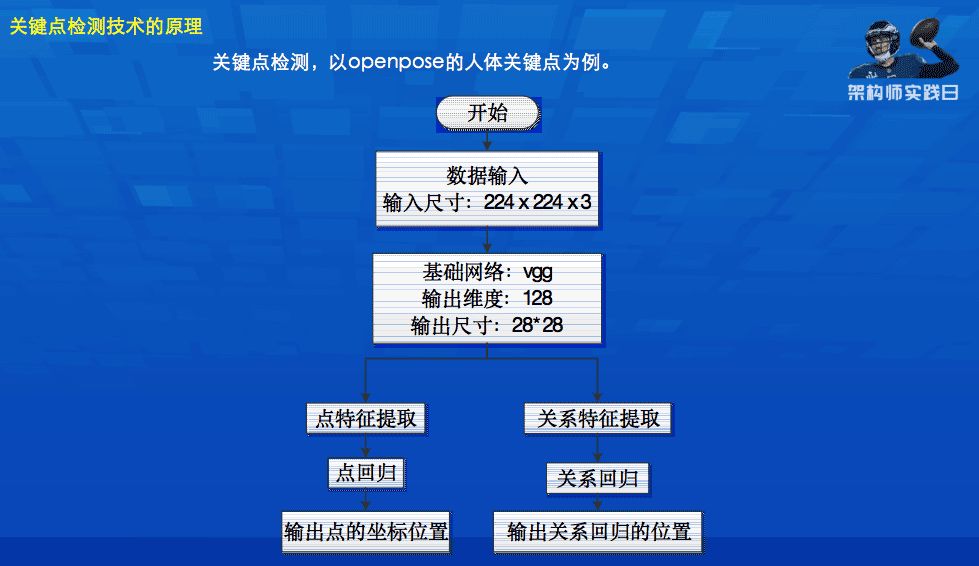
The network extracts features from the input image and passes through the basic segments. These features help to provide some material for key point regression and relationship regression. If the previous features are not rich enough, the results of subsequent processing will also be difficult to achieve the desired effect. This is also the main reason why large networks generally have higher accuracy in processing problems than small networks. But for small networks, keep these features, or propose features that are richer than the original large networks, but the space occupied does not need to be so large, so that it will have more accurate processing results than the large networks in the past and occupy Space and efficiency can be seen in this exploration. This exploration will be used in many autonomous driving. All algorithms need to be tested on the car, and they need to be run in real time on the embedded board, rather than on other larger platforms.
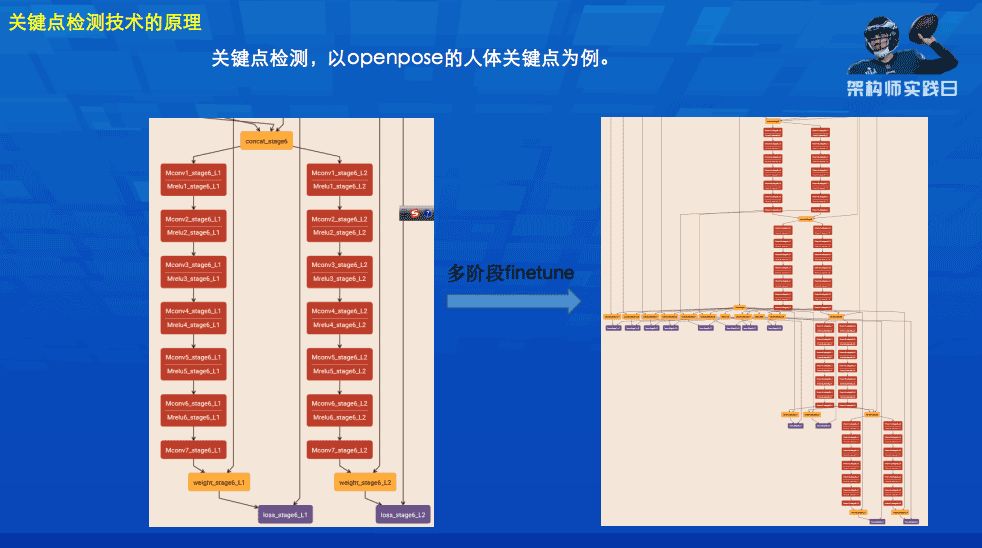
This is a relatively classic key point detection network. Its design is very simple: one branch returns to its point, and another branch returns to its relationship. Both the point label and the relationship label are defined in a similar way to the above figure. This method of definition reduces the difficulty of regression. The multi-stage method used is equivalent to each stage providing us with a certain result. In the next stage, a multi-stage accuracy experiment is performed on this result. In our no detection or other segmentation, there are many similar methods in other fields.
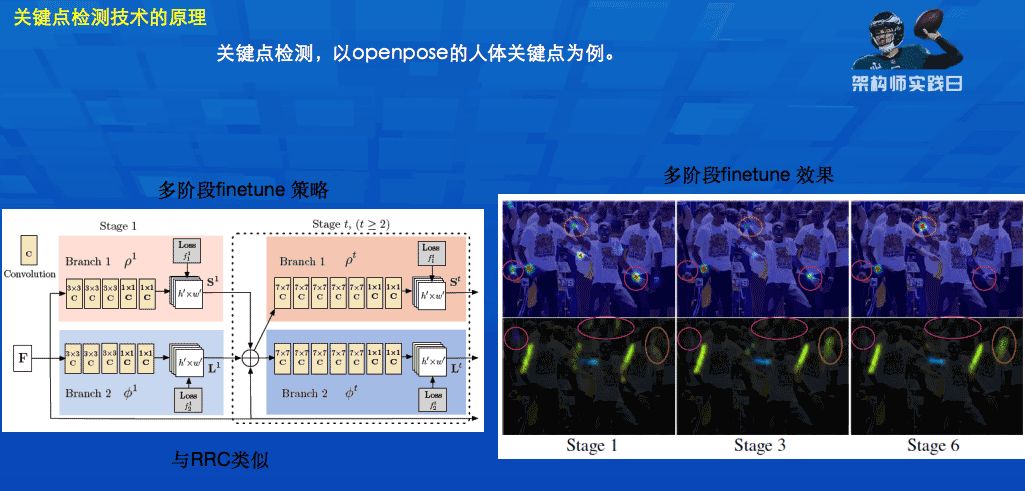
As can be seen from the above right figure, the effect of the points seen through the multi-stage accuracy is continuously improving as a whole. Even if individual points may drop, this is also a normal situation, because it has done multiple stages Fusion. This processing method is relatively common among processing methods based on deep learning. The return of the relationship now has undergone such multi-stage refinement, which can consider or integrate information at various stages, and its processing results are constantly improving. This method is often used in our three-dimensional vehicle detection or two-dimensional detection.
In the key point detection, the regression of the relationship is a very important one. For the definition of relationship, you can define a part of the relationship between two points, or define a relatively narrow field to do. This is the definition of a field often mentioned in our papers.

The definition of the field is equivalent to a certain enhanced definition of it within the scope of a domain, including position and orientation, etc. This is a multi-dimensional consideration. This method can help us solve that multiple targets and relationships appear in a picture or a detection task, and when multiple targets and points need to be connected to each other, this method has advantages. Because it will help us eliminate the wrong connection between points of different labels, and it can also help eliminate some points that do not meet the relationship constraints.

Take the openpose method just now as an example. Its regression accuracy is limited by the multiple of the image downsampling. For example, in the MIT paper, its accuracy is within a pixel range of 8 x 8.
If we want to improve the accuracy of our regression, there are two ways: one is to reduce the download multiple and try to do this on the big picture. The original author didn’t do this on the big picture because he couldn’t get such good results on the big picture. The bigger the picture, the more difficult the regression, that is, the greater the scope of the regression. Therefore, such a down-sampling was adopted, The difficulty is reduced.
Versatility of key point detection
This general key point can be reflected in the following aspects:
In autonomous driving, people's behavior can be found through this key point. For example, a security guard is waving at us in the parking lot. This parking space is for special purposes, and you cannot park. Or in some driving environments, do some key points of the face detection to help us identify the emotions and mental states of the drivers. On the other hand, this method can be used to help identify some puppies that suddenly appear on the side of the road. In the process of running our self-driving vehicle, if we encounter this kind of problem, we must identify not just a simple obstacle, but an uncontrollable animal. We must also identify its movements through key points. Squat or cross this road.
Secondly, when the vehicle is running outside, we observe some road signs on the road, such as road signs, arrows on the ground, or other key signs. These marked points can help us locate and can be found on the map. These positioning points, through these points, we can assist us to obtain our real-time position more accurately, and play a more precise role in positioning.
03
Application of key point detection in autonomous driving
In autonomous driving, there are some key point detection applications.

For example, the detection of an arrow. When the arrow is detected, its key nodes can be returned. Different color points represent different types, and different points have their position information. Through these points, as coordinates on the map, you can tell the vehicle in real time and accurately, and tell the autonomous driving brain that we are now. The key point detection of the arrow also uses a similar method. Although its network model has been changed beyond recognition, its principle is the same. Through different levels of pyramid levels, different levels of point information can be merged, thereby Improve its accuracy and on the other hand increase its detection rate.

Among the arrows or some other key points, it is also necessary to know the connection relationship between each point and another point, that is, the return of its relationship.

Not all point regressions can be very accurate. For example, some points are on the image. During the operation of the vehicle, the key points of some arrows can be accurately returned, and some may be identified incorrectly. This is limited by the experience we have learned before. This kind of problem can be improved through some follow-up, such as the improvement of the network, the improvement of the camera itself. In addition, you can also use other formulas in the later period, one more frame or matching method used in other algorithms to correct the error.


In addition, in automatic parking or autonomous parking, the parking space needs to be detected first, and we can use the point return method to return the top of the parking space. In an image, you can return to some key points in the parking space, and there are different types of key points. Through the key points of the parking space, we can accurately know the distance between our actual car or the vehicle itself and the distance between these key points and the parking space. We need to adjust the control module so that we can automatically park in this parking space. Therefore, the returned top information of parking spaces is very important information for our automatic parking or autonomous parking.

In addition, using point regression, combined with semantic segmentation, can give a more informative result. The network can output this result, which is equivalent to the segmented parking information, the number of vehicles in the garage, and the parking space. It is not an empty parking space, and whether this area is an empty parking space.

At the same time, through point regression, in another branch of the network, you can get the location of the key point. For example, we know that this place is an empty parking space, and we also know the location of its parking space, so for our automatic parking, we can stop directly, which is a good perception function.

In addition, in some outdoor positioning, the key point return method can be used to return to the fixed point of the street sign. You can know our real-time location more accurately through this point feedback on the map. For street signs, 2D target detection cannot fully describe its information, because there are many oblique street signs in the image. Through point regression, you can clearly get its true shape and position in the image. Through some camera imaging principles, or other correction methods, this position information can be projected into the real three-dimensional information, which can better help us determine the position of the vehicle itself in the three-dimensional world.

In the image as a two-dimensional bounding box or a three-dimensional bounding box for target detection, the remaining vertices after the relationship between points can actually be regarded as key points. The removed relationship is its box, and It is its connection relationship. Therefore, after removing the connection, it can be regarded as a point regression problem. In target detection or three-dimensional target detection, the more important research question is how to make this point regression problem more accurate. Many people use some template methods. For example, in Baidu’s Apollo 2.5, there is actually a mode that is equivalent to matching the real 3D candidates here, and see which one is closer or more similar to the detected one. match.

This method, other companies have a similar situation, when doing point regression, they do three-dimensional point regression directly in the picture, because two-dimensional point regression is relatively similar. We can see that when we are far away, we can do two-dimensional regression directly, and when we are a little closer, we can do three-dimensional point regression. Because it is difficult to see this profile when it is far away, it can be accurately described when it is relatively close. The hypotenuse below the target vehicle represents its heading angle. This heading angle is not the same as the public heading angle, and is equivalent to the heading angle of the car body. This heading angle is important to us. It can be judged or It assists us in judging the trend or range of movement of the vehicle ahead.
Because combined with multiple frames of information, the heading angle will have a changing curve. Based on this curve, we can predict whether the vehicle has a lane change or whether it has a tendency to turn sharply. Through such information, it can help the decision-making module to make some important decisions. For example, it is predicted that the vehicle ahead will jump in the queue. Preventing the jump in the queue is also a very important problem encountered in our automatic driving; for example, in many cars, in the L1 and L2 schemes, in the trial programming, if the vehicle in front wants to jump in the queue, right It is difficult to identify our self-driving vehicles. Whether the car in front has a tendency to jump in line is generally judged accurately or with the highest accuracy by a driver with a certain amount of experience. Because whether it can be judged that the driver of the vehicle ahead has a tendency to jump in line, for our normal human drivers, it has also caused many accidents. Because it is impossible to judge whether the vehicle in front has a tendency to jump in line, and many novice drivers in front suddenly change lanes, some classic collisions or rear-end collisions will occur. Such accidents can theoretically achieve higher accuracy than humans when placed on autonomous vehicles.
The point regression method can solve the problem of 3D target detection in some scenes. For point regression, it is necessary to judge whether the point should be here based on the surrounding relationship. In 3D detection, there are often problems with incomplete targets or occlusions. This requires us to increase its perception range or enhance its processing capabilities in this area, which can be effectively avoided. thing.

You can use some small networks to do it. For example, this table describes the use of different methods to return points to different tasks, such as human bodies, arrows, parking spaces, road signs, vehicles, etc., and many other types of point returns Tasks can be solved in this way. Generally speaking, they can be solved, but the processing capacity is limited. For example, in terms of the key points of the vehicle, when the key points of the vehicle are returned, the effect of the overall regression is average, because the vehicle itself is also a difficult problem, and the overall accuracy is much lower than that of 2D. At present, the method with higher accuracy is still assisted by lidar data. The method based on vision has not yet made the top three, or even only ranked in the top ten.
On the other hand, when using the classic mask-rcnn method to do this kind of problem, it is also limited by the accuracy problem just mentioned. The higher the multiple of downsampling, the more difficult it is to guarantee the accuracy of the result obtained by the regression. In this regard, many cascading methods are used to improve accuracy. For example, first use a 28 x 28, then 56 x 56, and then use a 112 x 112, so that the accuracy is gradually improved, but the amount of calculation is not Is improved, or the complexity has not been improved, it is not the relationship of multiplication but the relationship of addition, and the two strategies are used to do things. This should not be a difficult problem among our algorithm engineers or the same industry.
04
Several problems in key point detection at present

The above three points are the three typical types of problems we encountered in the exploration point regression task.
In addition, in scenes such as urban roads, parks, and parking lots, point return tasks or key point parking tasks can have more applications. Anything that can be abstracted as a typical position and key representative point can be abstracted into some points. These points can be regressed and detected using this technology, thereby improving our perception and processing capabilities.
05
Future development direction and potential
1. Versatility
It refers to the need to be able to return many types of points in a network and make them all. Rather than saying that to do a task, you need a network, because the network is inherently small. The versatility is that we have to use a network to do the regression of many types of tasks.
2. Miniaturization
On the basis of the network, a smaller but still richer network can be used. At present, the size of 1-2M can also be used, although the normal VGG16 is about 500M. Even so, the model information still has a lot of redundancy, and there is still much room for exploration.
3. Higher accuracy
Some accuracy is limited by the resolution of the mask downsampling, or the multiple of the downsampling. This is to improve the processing power of the algorithm so that the position of the point can be returned in a larger search space, that is, to reduce the multiple of the downsampling to improve the accuracy.
4. Stronger generalization
I have encountered a lot of problems where the candidate frame can't come back even if the key point is slightly off. In this case, it is necessary to improve the algorithm's ability to adapt to the candidate frame offset, or find ways to reduce or weaken the problem of candidate frame offset. This is also a common problem faced by many companies or research institutions that do autonomous driving solutions. Everyone has been trying to make methods with stronger generalization capabilities.
We provided various good quality Alarm Vehicle siren Speaker with high quality sound. Some can be mounted into lightbar, also can be used separately. with excellent workmanship and high reliability. Technical specifications are in accordance with international standard. You can choose High quality Thick aluminium alloy shell or ABS plastic material model.advantages are:compact structure design,fashion appearance,simple installation , water proof and aquosity proof,corrosion resistant and anti-vibration.Mainly adopting Nd-Fe-B magent with high electroacoustic transmission rate and electricity-sound exchange, efficient and wide frequency range.Technical specifications are in accordance with international standard. Customized Power are accepted. Customized Colors are accepted. OEM and ODM orders are welcome

Vehicle Alarm Speakers,Car alarm speaker,Emergency Vehicle Sirens,Siren Speaker,car alarm siren
Taixing Minsheng Electronic Co.,Ltd. , https://www.ms-speakers.com