Introduction to the classification method of the tasks that machine learning is responsible for
The classification of machine learning algorithms is tricky. There are several reasonable classifications. They can be divided into generation/recognition, parameter/non-parameter, supervision/unsupervised, etc.
For example, the document page of Scikit-Learn groups the algorithms through a learning mechanism. This produces categories such as: 1, generalized linear model, 2, support vector machine, 3, nearest neighbor method, 4, decision tree, 5, neural network, etc...
However, from our experience, this is not always the most practical way to group algorithms. That's because you don't usually think about applying machine learning. "Today I want to train a support vector machine!" Instead, you usually have a final goal in your mind, such as using it to predict results or classify observations.
So in machine learning, there is a theorem called "no free lunch." In short, it means that no single algorithm can solve every problem perfectly, which is especially important for supervised learning (ie predictive modeling).
For example, you can't say that neural networks are always better than decision trees, and vice versa. There are many factors at work, such as the size and structure of the data set. Therefore, you should experiment with many different algorithms for your problem while using the "test set" of the data to evaluate performance and select the winner.
Of course, the algorithm you try must suit your problem, which is why it is important to choose the right machine learning algorithm. For example, if you need to clean your house, you can use a vacuum cleaner, broom or mop, but you won't take out a shovel and start digging.
Therefore, we want to introduce another method of classification algorithm, which is to classify through the tasks that machine learning is responsible for.
Machine learning tasksRegression is a supervised learning task for modeling and predicting continuous numerical variables. For example, predicting real estate prices, stock price changes, or student test scores.
A feature of a regression task is a tagged data set with a numeric target variable. In other words, you have some "fact-based" values ​​for each observation that can be used to supervise the algorithm.
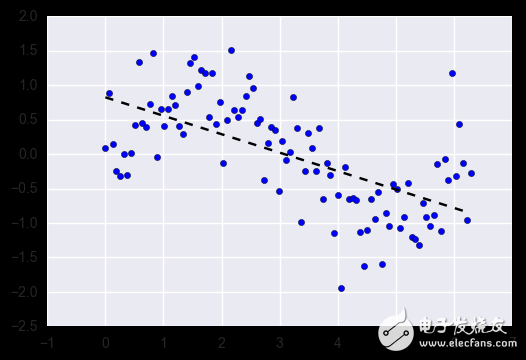
1.1. (regularization) linear regression
Linear regression is one of the most commonly used algorithms in regression tasks. Its simplest form is trying to integrate a straight hyperplane into your dataset (ie you only get one straight line when you have only two variables). As you might guess, when there is a linear relationship between the variables of the dataset, it works very well.
In fact, simple linear regression is often overlooked by regularized homogeneous algorithms (LASSO, Ridge, and ElasTIc-Net). Regularization is a technique that punishes large coefficients to avoid overfitting, and it should adjust the intensity of its punishment.
Advantages: Linear regression can be intuitively understood and interpreted, and can be regularized to avoid overfitting. In addition, the linear model can be easily updated using new data with a random gradient drop.
Disadvantages: Linear regression does not perform well when there is a nonlinear relationship. They are not inherently flexible enough to capture more complex patterns, which can be tricky and time consuming to add the right interaction term or polynomial.
Implementation: Python/R
1.2. Regression tree (integration)
The regression tree (a type of decision tree) achieves layered learning by repeatedly dividing the data set into separate branches, thereby maximizing the gain effect of each segmentation information. This branching structure allows the regression tree to naturally learn nonlinear relationships.
Integrated methods such as Random Forest (RF) and Gradient Enhancement Tree (GBM) combine the characteristics of many individual trees. We won't introduce their basic mechanics here, but in practice, random forests usually perform very well, while gradient-enhanced trees are difficult to adjust, but the latter tend to have higher performance limits.
Advantages: The regression tree can learn nonlinear relationships and is quite sensitive to outliers. In practice, the regression tree also performed very well and won many classic (ie non-deep learning) machine learning competitions.
Disadvantages: Unconstrained single trees are easy to overfit because they can keep branches until they remember all the training data. However, this problem can be alleviated by using an integrated approach.
Implementation: Random Forest - Python / R, Gradient Enhancement Tree - Python / R
1.3. Deep learning
Deep learning refers to a multi-layer neural network that can learn extremely complex patterns. They use a "hidden layer" between input and output to simulate data mediation codes that other algorithms are difficult to learn.
They have several important mechanisms, such as convolution and discarding, that enable them to effectively learn from high-dimensional data. However, deep learning still requires more data to train than other algorithms because these models require more parameters to achieve more accurate guessing.
Advantages: Deep learning is the most advanced method currently available in areas such as computer vision and speech recognition. Deep neural networks excel in image, audio and text data, making it easy to update data using bulk propagation methods. Its architecture (ie, the number and structure of layers) can accommodate many types of problems, and their hidden layers reduce the need for feature engineering.
Fiber Optic Cabinet,Fiber Cabinet,Fiber Distribution Cabinet,Outdoor Fiber Cabinet
Cixi Dani Plastic Products Co.,Ltd , https://www.dani-fiber-optic.com