How to make reptiles use these agents easier?
Reptile Agent IP Pool
In the company's distributed deep-web crawler, a stable set of agent pool services was established to provide effective agents for thousands of crawlers and ensure that each crawler obtains effective proxy IP for the corresponding websites, thus ensuring fast and stable crawlers. Running, of course, things done in the company cannot be open sourced. However, it's time to itch, so you want to use some free resources to get a simple proxy pool service.
1, the problem
Where does proxy IP come from? When I first learned reptiles, I didn't use agent IP to go to the site where I had to spur thorns, fast agents, or free agents, or there were individual agents. Of course, if you have a better proxy interface you can also access it yourself. Free agent collection is also very simple, nothing more than is: access page page -> regular / xpath extraction -> save
How to ensure the quality of the agent? It's safe to say that most of the free agent IPs are not available. Why else do people pay for them? (However, the fact is that many agencies' payment IP is also unstable and many of them cannot be used). Therefore, the collected proxy IP can not be used directly. You can write detection programs to use these agents to access a stable website to see if it can be used normally. This process can be used in a multi-threaded or asynchronous manner, because detecting the proxy is a very slow process.
How to store the collected agent? Here we have to recommend a high-performance multi-data structure NoSQL database SSDB for proxy Redis. Supports queue, hash, set, and kv pairs and supports T-level data. Is a good intermediate storage tool for doing distributed reptiles.
How to make reptiles use these agents easier? The answer is definitely to make a service, python has so many web frameworks, just take one to write an api for the crawler to call. This has many advantages, such as: When the crawler finds that the proxy cannot be used, it can actively delete the proxy IP through the API. When the crawler finds that the proxy pool IP is not enough, it can take the initiative to refresh the proxy pool. This is more reliable than the testing procedure.
2, agent pool design
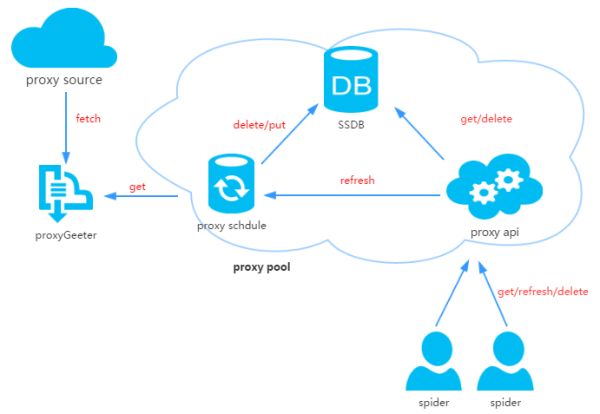
The proxy pool consists of four parts:
ProxyGetter: The agent obtains the interface. At present, there are 5 free agent sources. Each call will grab the latest agent of the 5 websites and put it into the DB. You can add additional agents to obtain the interface by yourself.
DB: Used to store the proxy IP. Currently only SSDB is supported. As for why we choose SSDB, we can refer to this article, personally think that SSDB is a good alternative to Redis, if you have not used SSDB, it is also very simple to install, you can refer to here;
Schedule: scheduled task users periodically check the availability of the agent in the DB and remove the unavailable agent. At the same time will also take the initiative through ProxyGetter to get the latest agent into the DB;
ProxyApi: the external interface of the proxy pool, because now the agent pool function is relatively simple, spent two hours watching Flask, happy decision to use Flask to get. The function is to provide get/delete/refresh interface to the crawler, which is convenient for the crawler to use directly.
3, the code module
Python's high-level data structure, dynamic typing, and dynamic binding make it well-suited for rapid application development, as well as being a glue language for connecting existing software components. Using Python to implement this proxy IP pool is also very simple. The code is divided into 6 modules:
Api:api interface related code, the current API is implemented by Flask, the code is very simple. The client request is passed to Flask and Flask calls the ProxyManager implementation, including get/delete/refresh/get_all;
DB: database-related code, the current database is using SSDB. The code is implemented in factory mode to facilitate the future expansion of other types of databases;
Manager: get/delete/refresh/get_all interface specific implementation class, the current agent pool is only responsible for managing the proxy, there may be more features in the future, such as the binding of agents and crawlers, agents and account bindings, etc.;
ProxyGetter: The relevant code obtained by the agent, currently crawls free agent of fast agent, agent 66, agent, Xixi agent, and guobanjia. It is tested that there are only sixty to seven agents available for the daily update of the five websites. , Of course, also support their own extended agent interface;
Schedule: Scheduled task related code, now only to achieve timing to refresh the code, and verify the available agents, using a multi-process approach;
Util: store some common module methods or functions, including GetConfig: read the configuration file config.ini class, ConfigParse: integration override ConfigParser class, make it case-sensitive, Singleton: implementation of singleton, LazyProperty: implementation class Property lazy calculation. and many more;
Other files: configuration files: Config.ini, database configuration, and proxy acquisition interface configuration. You can add new proxy acquisition methods in GetFreeProxy and register them in Config.ini to use.
4, install
Download code:
Git clone :jhao104/proxy_pool.git or directly to https://github.com/jhao104/proxy_pool Download zip file
Installation dependencies:
Pip install -r requirements.txt
start up:
Need to start the scheduled task and api respectively to Config.ini configure your SSDB to the Schedule:>>>python ProxyRefreshSchedule.py to the Api directory:>>>python ProxyApi.py
5, use
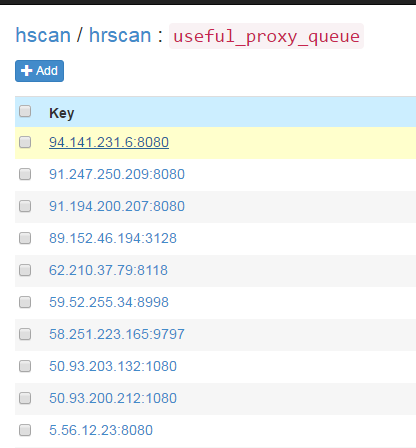
After the scheduled task is started, all agents are fetched into the database and verified by the proxy fetch method. After that, it will be repeated once every 20 minutes by default. About a minute or two after the scheduled task starts, you can see the available agents refreshed in the SSDB:
After starting ProxyApi.py, you can use the interface to get the proxy in the browser. Here is the screenshot in the browser: index page:

Get page:

Get_all page:

Used by the crawler. If you want to use it in a crawler code, you can encapsulate the api as a function directly. For example:
Import requestdef get_proxy(): return requests.get("http://127.0.0.1:5000/get/").contentdef delete_proxy(proxy): requests.get("http://127.0.0.1:5000/delete/ ?proxy={}".format(proxy))# your spider codedef spider(): # .... requests.get('https://', ​​proxies={"http": "http://{} ".format(get_proxy)}) # ....
6, the last
Time is rushed, functions and codes are relatively simple, and there is time for improvement. Like to give a star on github. thank!
All in one pc is a new trend for desktop type computer nowadays. What you can see at this store is Custom All In One PC. There are 19 inch all in one pc, 21.5 All In One PC, All In One PC 23.8 Inch and 27 inch all in one pc, which are the main sizes at the market. How to choose the most suitable one for special application? According to clients` feedback, 19.1 inch entry level, 21.5 inch middle and low level, 23.8 or 27 inch higher level-All In One PC I7. Some clients may worry the heat-releasing since equipped releasing fan into the back of monitor, see no releasing fences on back cover. However, totally no need worry that point, cause special back cover material and releasing holes can meet the demand of heat releasing.
You can see All In One Business Computer, All In One Gaming PC, and All In One Desktop Touch Screen series at this shop.
Any other unique design or parameters, just feel free to contact us so that can get right and value information quickly.
Believe will try our best to support you!
All In One PC,All In One Pc I7,Custom All In One Pc,All In One Pc 23.8 Inch,21.5 All In One Pc
Henan Shuyi Electronics Co., Ltd. , https://www.shuyicustomtablet.com